Task Arithmetic (Task Vector, Model Merge)

-
왼발 손흥민 + 오른발 손흥민 => 양발 손흥민
-
좌타 레이예스 + 우타 레이예스 => 스위치 히터 레이예스
-
안전한 모델 + 성능 좋은 모델 => 성능 좋고 안전한 모델?
-
Editing Models with Task Arithmetic
-
ICLR 2023 Poster, University of Washington, MS research, Allen AI
요약
"모델의 파라미터끼리 마치 벡터 연산처럼 더하거나 빼서 능력을 더하거나 뺄 수 있다."
끝.
좀 더 자세히 설명해봐요...
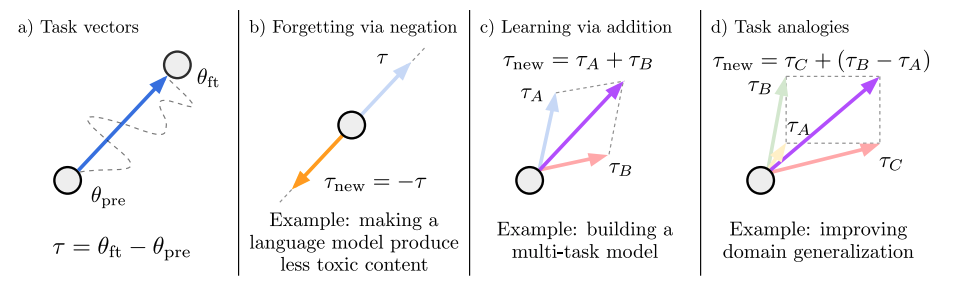
이 그림을 보자.
Task Vector
먼저, Task Vector라는 것을 알아야 한다.
Task Vector
여기서
그러면 파라미터끼리 빼면? 어떤 벡터가 나온다는 것이다. 다시 말해 파인튜닝을 하면서 변화한 파라미터 벡터가 나오는 것이다.
이게 Task Vector다.
만약 "안전한 모델"로 파인튜닝을 했다면? (안전한 모델 파라미터) - (원래 모델 파라미터) => 안전함을 의미하는 Task Vector!
만약 "욕쟁이 모델"로 파인튜닝을 했다면? (욕쟁이 모델 파라미터) - (원래 모델 파라미터) => 욕쟁이를 의미하는 Taks Vector!
빼기 연산
어떤 모델이 "욕을 하지 못하도록" 만들고 싶다.
그러면 일단 "욕쟁이 모델"을 파인튜닝 한 후에, 욕쟁이 Task Vector를 구한다.
그 다음에 base 모델에서 욕쟁이 Task Vector를 빼주면 모델은 더 이상 욕을 하지 못한다!!
더하기 연산
어떤 이미지 분류 모델이 있다.
A라는 모델에는 강아지 관련 데이터를 넣어 파인튜닝 시키고, B라는 모델에는 고양이 관련 데이터를 넣어 파인튜닝 시켰다.
이제 나는 강아지와 고양이 둘 다 잘 분류하는 이미지 분류 모델을 얻고 싶다! 그러면 어떻게 하면 될까?
A+B를 한다. 정확히는 각각의 Task Vector를 더해줘서, 그 Task Vector만큼 베이스 모델의 가중치를 이동한다.
더 복잡한 연산
여러분은 '배민'의 음식점 리뷰를 보고 감정 분석을 수행하는 모델을 만들 것이다.
근데 그것에 대한 레이블은 없다 (배민 음식점 리뷰 - 감정 분석 pair가 부재)
대신에, 쿠팡 제품 리뷰에 대한 감정 분석 데이터는 있다! 심지어 쿠팡 제품 리뷰를 바탕으로 한 감정 분석 모델도 있다고 하자.
그러면 어떻게 배민 감정 분석 모델을 만들 수 있을까? 간단하다.
여기서 'sent'가 붙은 모델은 감정 분석용 모델, 'lm'은 general한 language modeling이다.
여기서 한 것은, 쿠팡이라는 도메인에서 배민이라는 도메인으로 욺겨가면서도, 쿠팡에서의 감정 분석 능력만 슬쩍 더해준 것이다!
이게... 어떻게 가능하죠?
논문에서는 각각 다른 데이터로 학습하거나, 다른 task를 학습할 때, 모델에서 학습이 주로 되는 파라미터들이 상당히 차이가 많이 난다. 다른 말로 하면, 각 task vector들은 orthogonal하다. (더 어렵죠?)
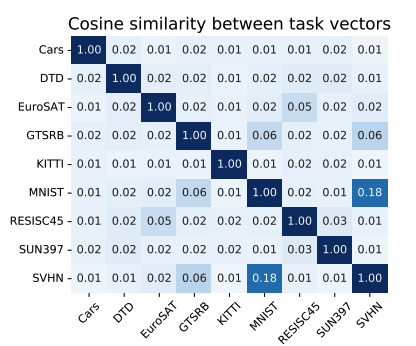
각 Task Vector들의 Cosine Similarity (유사도)를 나타낸 heatmap이다. 대부분 0에 근접한 정도의, 매우 다른 Task Vector들을 보여준다. 유독 혼자 0.18인 MNIST-SVHN은 아주 유사한 데이터셋이다.
즉, 다른 Task들은 학습될 때 다른 부분의 파라미터들을 주로 움직이고, 그래서 두 개를 합쳐도 서로의 능력이 보존된다는 것이다!
실험
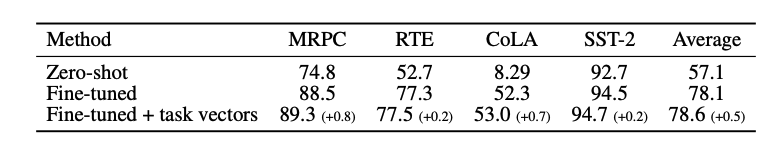
GLUE 벤치마크 (텍스트 분류 task)의 점수이다. GLUE 데이터셋으로 파인튜닝을 한 것에 더해, 다른 데이터셋으로 학습한 task vector를 더해주니 성능이 더욱 올라가는 것을 볼 수 있다. (정확하게는 다른 데이터셋으로 학습한 모델을 Huggingface에서 다운받아서 더해준 것이다.)
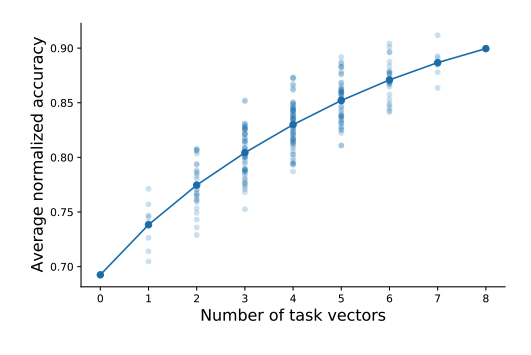
여러 다양한 데이터셋으로 학습한 각각의 모델들을 합쳐 보았다. 더 많은 모델을 합칠수록, 평균적인 정확도가 올라가는 모습을 볼 수 있다.
즉, generalization에도 효과가 있다.
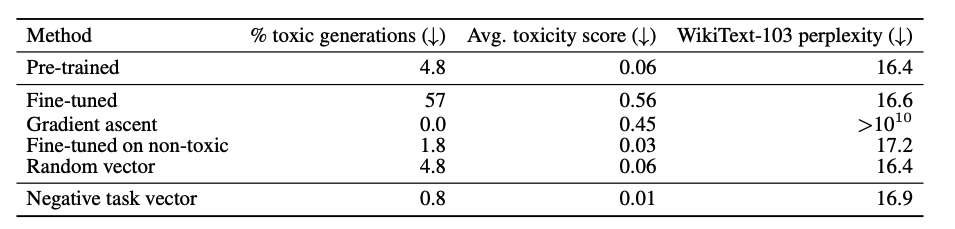
toxic generation (LLM이 욕하는 것과 같은 것)을 방지하는 데에도, task vector를 빼버리는 것이 효과가 있음을 보여주었다.

아까 쿠팡과 배민의 예시다. 위에서 들었던 예시에서 "배민"이 target이라고 보면 된다.
Fine-tuned on auxiliary는 배민이 target이면 쿠팡으로 튜닝했을 때.
Fine-tuned on target이면 배민이 target일때 배민으로 튜닝한 것이다.
Task analogies가 Task vector를 이용해 만든 모델이다.
꽤나.. 괜찮죠? 실제로 Fine-tuned on target은 불가능 (unlabeled dataset이므로)하다는 것을 기억하자.
결론
-
multitask learning? 뭐... 그냥 따로 훈련한 다음에 모델 합치면 그만인데;;

-
p.s. 물론 LLM 등에서 제대로 이러한 Model Merge를 쓰려면 TIES 등의 기법을 쓰는 것이 더 좋은 결과를 가져온다. 기회가 된다면 다음에 다뤄보도록 하겠다.