Scalable and Effective Generative Information Retrieval

- Generative Retrieval, 들어는 보셨나요??
- 논문
- WWW 2024 Oral
Generative Retrieval이란?
Generative Retrieval의 기본적인 아이디어는 간단하다. 유저가 물어본 질문에 대하여 모델이 관련된 문서의 ID를 생성해주면 안될까?
잠깐만... 문서의 ID를 생성한다고? 문서의 내용도 아니고, 임베딩 모델을 쓰는 것도 아니라 갑자기 ID를 내뱉는 모델은 사뭇 당황스럽게 다가오기 까지 한다.
그런데 한 번 직관적으로 생각해보자...

한 대형마트의 점원을 생각해 보자. 보통 점원도 아니고, 일한지 오랜 세월이 흘러 물건 배치 하나 하나를 낱낱이 알고 있는 그런 점원 말이다. 한 손님이 다가와 점원에게 다음과 같이 물어본다고 하자.
손님 : "혹시 올리브 오일이 어디 있나요?"
점원 : "매장 앞쪽에 네 번째 '기름류'에 가시면 중간 즈음에 올리브유가 있습니다."
자 여기서 점원이 한 것이 바로 문서의 ID를 내뱉은 것이다! 올리브유라는 문서는 '앞쪽 - 네 번째 - 중간'이라는 ID를 가지고 있는 것이다. 점원은 수많은 손님들의 "이거 어디 있어요?" 쿼리와 실제 문서 (찾는 물건)의 위치가 학습되어서, 정확한 물건의 위치를 말할 수 있는 것이다.
그러면 우리가 가지고 있는 문서 더미에 대해서, 위의 마트 점원과 같이 "내가 질문하면 문서의 ID를 말해주는" 모델을 만들어보도록 하자.
1. 문서 ID 생성
먼저 문서 ID를 잘 생성해야 한다. 아무 규칙도 없이 마구잡이로 문서에 ID를 붙인다면, 전혀 정돈되어 있지 않기 때문에 모델이 ID를 찾는 법을 학습할 수 없다. 마트의 모든 물건을 거대한 수영장에 넣어서 섞은 후, 거기서 원하는 물건을 찾아보라고 하는 장면을 생각해보자.

아무래도 원하는 물건을 찾기가 매우 힘들 것이다.
이 ID를 정하는 방법은 여러 가지가 있다. DSI라는 방법론에서는 의미론적으로 어떤 규칙을 가지고서 문서의 ID를 생성하기 위해서 임베딩 모델을 활용한다. 문서들을 모두 임베딩 한 이후에, 임베딩 벡터를 기준으로 계층적인 K-means 클러스터링을 수행한다. 계층적이기 때문에, 마치 나무와 나뭇가지들처럼 상하관계가 있는 군집이 형성된다. 이제 큰 가지에서 세세한 가지로 가는 순서대로 ID를 매긴다.
마치 야구 선수를 나눌때 "팀 군집 - 투/타 군집 - 포지션 군집 - 출생연도 군집" 등과 같이 나눈다고 생각하면 된다. 그러면 "김도영"이라는 야구 선수는 "기아 - 타 - 3루 - 2003"과 같은 아이디를 가지게 된다.
2. 모델 구조
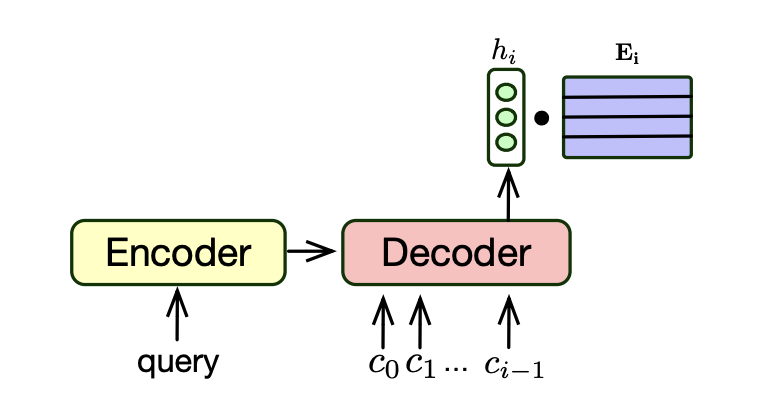
보통 다음과 같은 Encoder-Decoder 구조를 사용한다. 인코더에 쿼리를 넣고, 디코더에서 문서의 ID를 이루는 토큰을 AutoRegressive하게 생성한다.
Decoder에서 나온 hidden state는 문서 ID 토큰 임베딩 테이블이다. 이를 통해서 문서 ID 토큰이 생성될 확률이 나오고, 이를 beam search를 통해 선택하게 된다.
3. 훈련
훈련은 당연히 쿼리와 정답 문서 ID 쌍이 필요하다. 그러면 이를 단순한 분류 문제로 볼 수 있으므로 Cross Entropy Loss 등을 쓸 수 있다. 물론, 방법론마다 loss는 달라질 수 있다.
기존 Generative Retrieval의 문제
- 인공적으로 짜여지거나 작은 규모의 데이터셋에서만 실험적인 효과가 입증되었음.
- MSMARCO와 같은 상황에서는 BM25가 Generative Retrieval보다 3배 좋게 나왔다!
솔루션
이 논문에서는 기존의 generative retrieval의 성능적 한계를 극복한 방법인 RIPOR을 제안한다. 이제 해당 방법론을 자세히 알아보자.
Prefix-Oriented Ranking Optimization
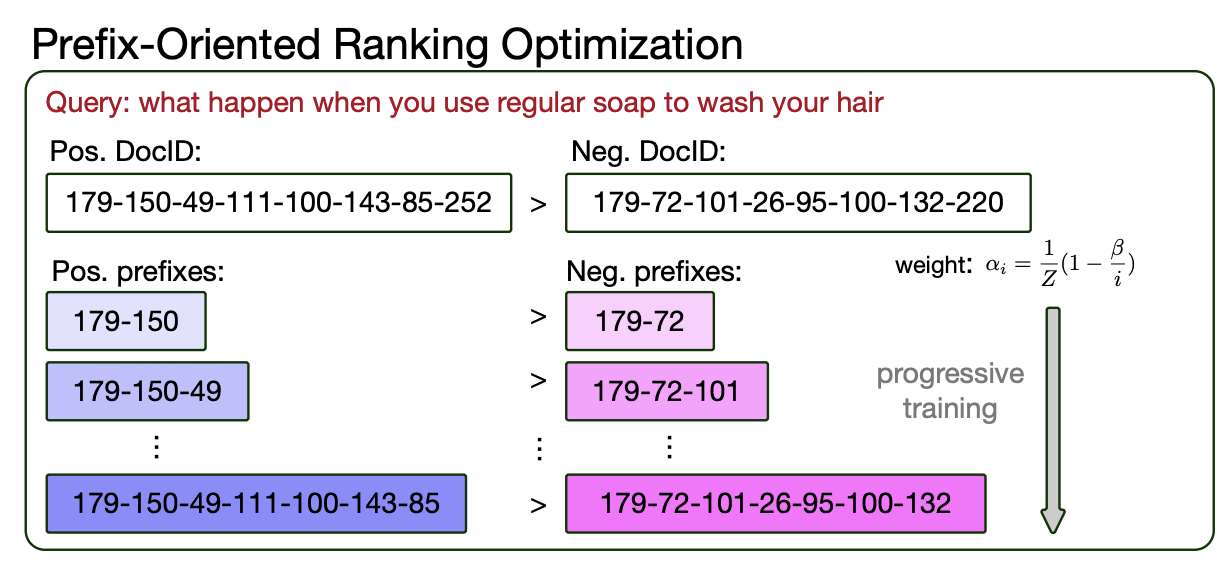
LTRGR과 같은 기존 방법론은 쿼리와 positive doc, negative doc의 triplet을 사용해서 loss를 계산하고 훈련했다. generative retrieval 모델이 해당 Doc 아이디를 생성할 확률이 곧 스코어
이런 방법은 AutoRegressive한 생성 방식과 beam search 디코딩 방식에 그다지 어울리지 않는다. 왜냐하면, 분명히 한 토큰씩 생성하는 구조인데 전체 Doc Id만 고려하기 때문이다.
그래서, ID의 첫 번째부터 마지막 순서에 가기까지 모든 토큰 시퀀스들을 활용할 것이다. 위의 그림에서 처럼, "179-150-49-111-100-143-85-232" 딱 하나만 활용하는 것이 아니라,
"179-150", "179-150-49", "179-150-49-111" ... "179-150-49-111-100-143-85-232" 까지 활용하는 것이다.
MarginMSE
MarginMSE라는 loss 함수가 있다. 수식부터 살펴보자면,
여기서
이 loss는 보다시피 앞에 -가 붙어있지 않다.
이렇게 된다. 즉, 이것의 주요 목적은 cross encoder 모델에서 나온 점수와 훈련하는 모델에서 나온 점수가 비슷하게 나오도록 하는 것이다. 그래서 이 loss에서 cross encoder 모델은 Teacher Model이다.
Loss function
위의 loss 함수가 실제 논문에서 쓴 loss이다. 기본적으로는 MarginMSE와 매우 비슷한데, 일단 각 토큰 위치
왜냐하면, 수식에서 보다시피
Progressive Training
처음부터 잘 Doc ID를 생성하는 능력을 훈련시키기 위하여, 먼저 짧은 ID들 부터 훈련하고 그 이후로 긴 ID를 훈련하는 형태로 학습을 진행했다.
근데, 그냥 학습하면 긴 ID 훈련할 때 짧은 ID를 생성하는 능력을 까먹는 문제가 있었다.
이를 해결하기 위해, Doc ID 생성을 훈련할 때에 그 앞 토큰을 생성하는 loss 또한 같이 추가해주었다.
이러면 ID 앞쪽을 생성하는 능력도 까먹지 않았다.
Relevance-Based DocID Construction
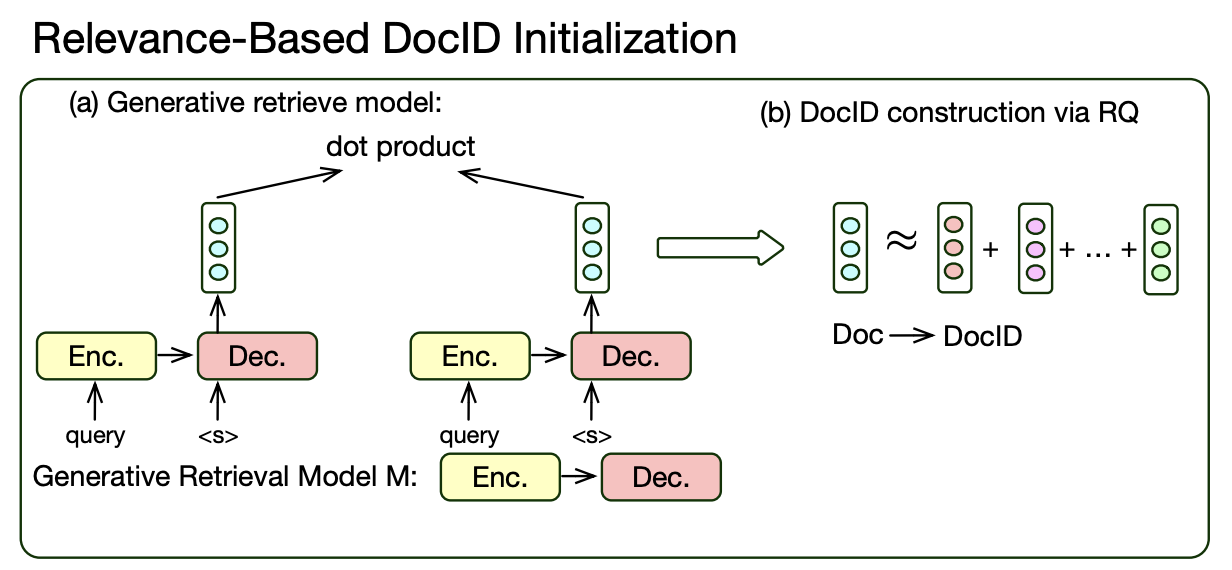
앞에서 Doc ID를 잘 만드는 것이 매우 중요하다고 했다. 이 논문에서는 Doc ID를 만드는 방법 또한 제안한다.
Doc ID를 잘 만드는것은 진짜 진짜 중요하다. 먼저, Doc ID는 그 안에 문서들끼리의 연관성을 나타낼 수 있어야 한다. 비슷한 ID를 가진 문서는 의미론적으로 비슷해야 할 것이다. 또한, beam search로 AutoRegressive하게 생성되기 때문에 ID는 반드시 계층적인 구조로 이루어져야 한다.
이 두 가지 조건이 충족되어야 Doc ID를 잘 만들었다고 할 수 있겠다.
이를 위해서 RVQ, 즉 Residual Quantization을 적용했다. Document Embedding에 대해서 여러 번 다른 방식으로 clustering을 수행하고, 그 cluster에서 대표 벡터를 뽑는다. 여러 번 수행하기 때문에 한 document에 대해서는 여러 대표 벡터들이 나오게 된다. 그것들을 모두 더한 것이 해당 Document Vector가 된다. 그리고 여기서는 RVQ 과정에서 나온 각각의 대표 벡터들이 Doc ID의 토큰으로 변환될 수 있다.
이 때 임베딩을 생성하는 모델은 다른 것이 아니라 바로 generative retrieval 모델이다! special token을 넣어준 후, 거기서 나온 hidden state를 곧 임베딩 벡터로 사용하는 방식이다. 이 generative retrieval 모델은 먼저 MarginMSE와 query-pos-neg 문서 triplet으로 훈련된다.
실제 훈련 방식

1. DocID 만들기
먼저, BM25를 이용해서 top-K개의 문서를 각 쿼리에 대해 가져온다. 이 때, positive document label이 존재하는 데이터셋이므로 MarginMSE를 통해 훈련한다. 훈련이 완료되면, 해당 모델을 임베딩 모델로서 사용한 후에 top-K개의 문서를 또 뽑아서 훈련한다. 그리고 나서 RVQ를 이용해 DocID를 만든다.
2. Pretraining
Seq2Seq pretraining을 수행한다. 각 Document들을 보고서 Doc2Query 모델로 가짜 query 여러개를 생성한다. 그리고 이 가짜 쿼리들을 이용해서, CE(Cross-Entropy) loss로 쿼리에 대해 해당 문서 ID를 생성할 수 있도록 훈련한다.
3. 파인튜닝
- 첫 번째 파인튜닝 : 먼저, 그냥 MarginMSE가 아닌 앞에서 제안한 (Doc ID 내 토큰의 위치 별로 다른 가중치를 가지는) Loss를 이용해서 훈련한다. 이 단계에서는 pretraining 이전의 모델에서 생성한 임베딩을 이용해 top-K개를 샘플링한다.
- Prefix-Oriented Ranking 최적화 : 튜닝을 마친 모델로 "생성"과 beam search를 통해 top-100개의 Doc ID를 만든다. 이 데이터셋을 앞서서 사용한 데이터셋과 합쳐서, 앞에서 제안한 훈련 방식대로 훈련한다. (Progressive Training)
- Self-Negative 파인튜닝 : 앞서서 완성된 모델로 "생성"과 beam search로 또 다시 데이터셋을 만든 후, 그것으로 다시 훈련한다. (Progressive Training loss 사용)
실험 결과
실험에 데이터셋으로는 Information Retrieval 데이터셋으로 유명한 MSMARCO와 TREC DL19, DL20을 사용했다. 즉, Open-Domain 데이터이다.
실험에는 A100 40GB 8개...를 활용했다고 한다.
베이스라인으로는 다른 generative retrieval 모델은 물론 BM25, DPR (우리가 아는 임베딩 모델을 사용한 것), MarginMSE 등의 Dense 및 Sparse Retrieval 방식도 사용했다.
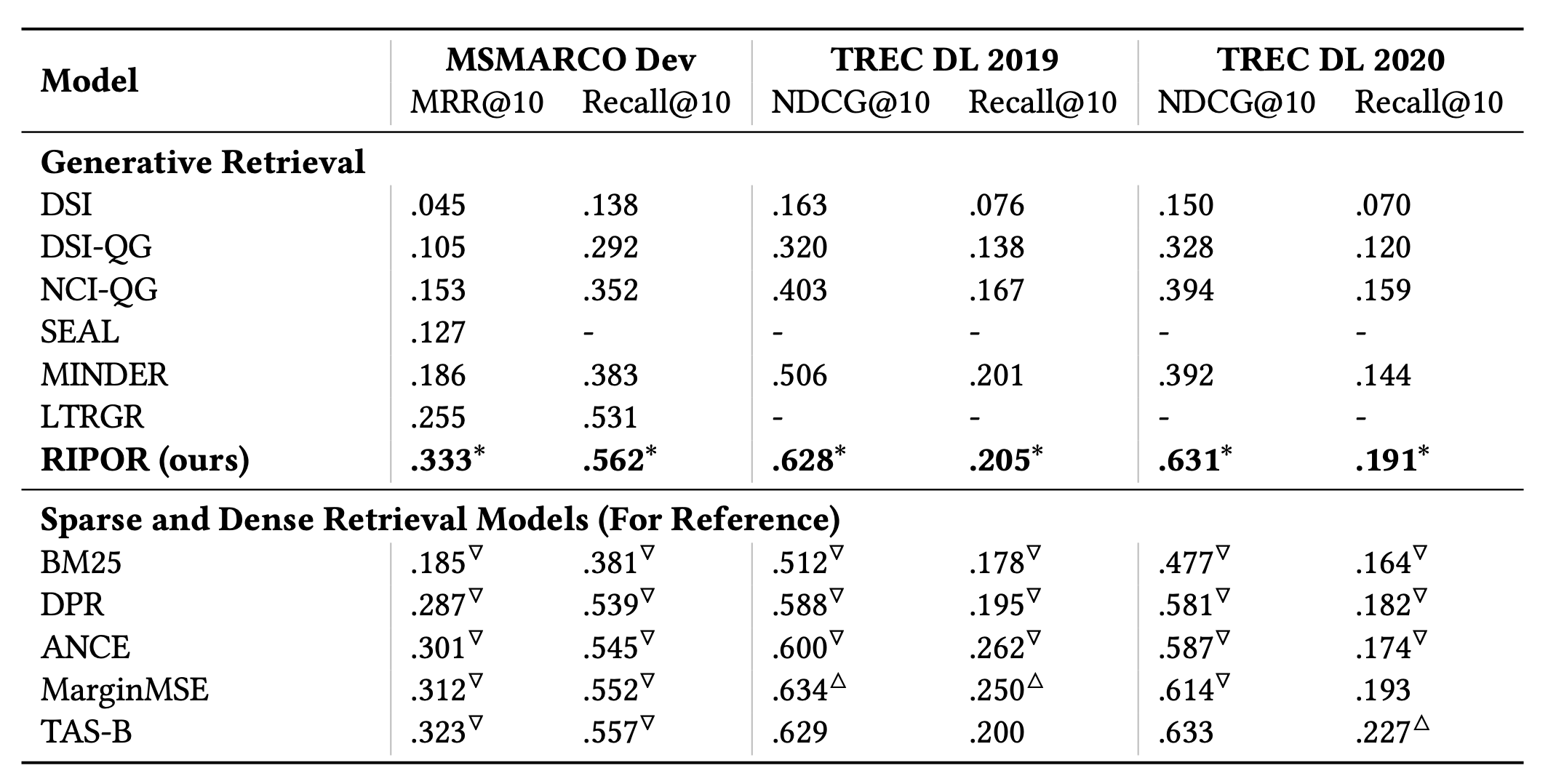
결과를 보면 알겠지만, 일단 다른 generative retrieval보다 훨씬 월등한 성능을 보여준다. 그래도 MarginMSE나 TAS-B 등 dense retrieval 방법론이 소폭 우세한 성향을 보이는 것도 발견할 수 있다.
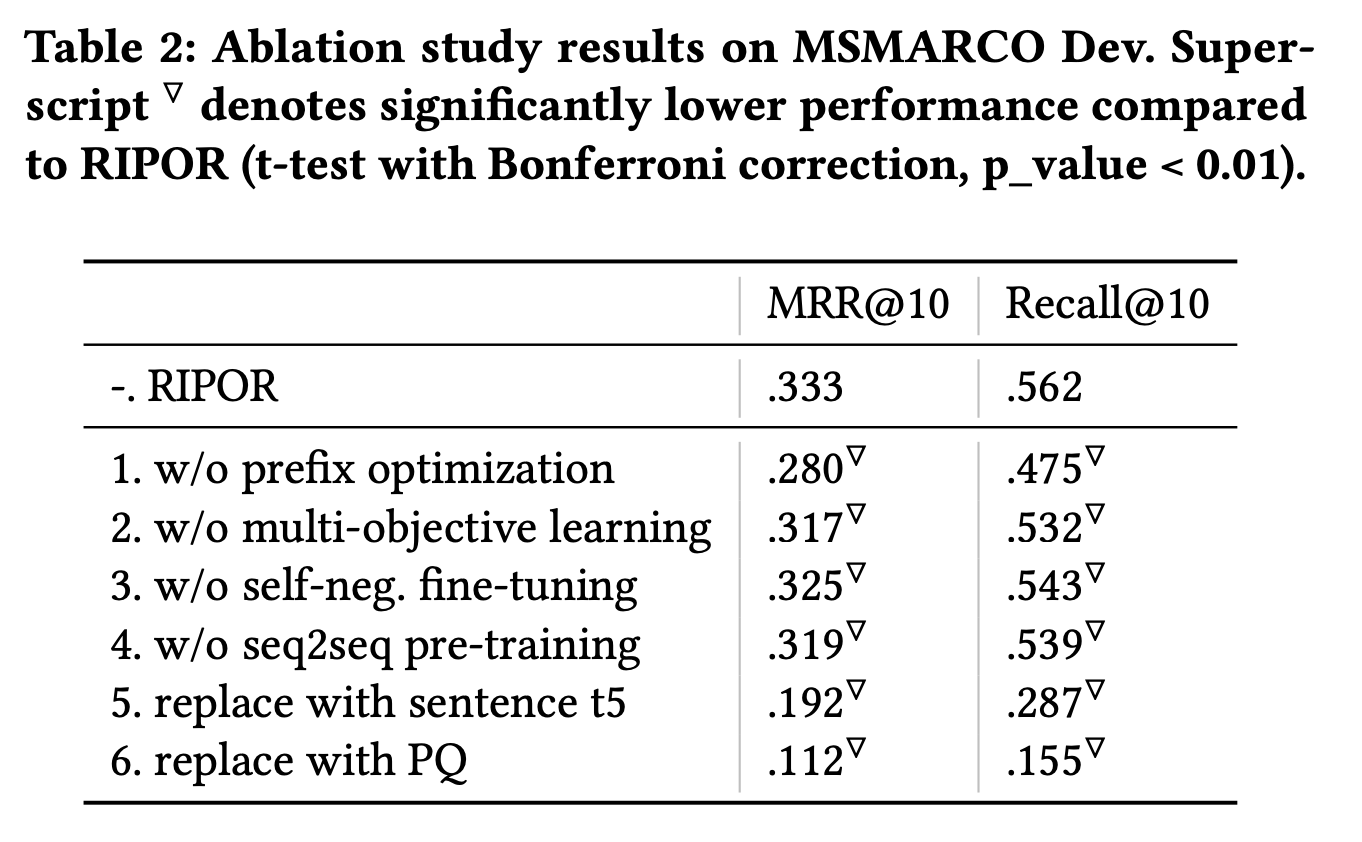
각 단계들을 안하고 훈련했을 때의 Ablation Study다. 모두 성능에 꽤나 중요한 단계임을 볼 수 있다.
느낀 점
- generative retrieval이라는 개념 자체가 굉장히 신박하고, 앞에서 설명했다시피 직관적으로 생각하면 뭔가 말이 된다.
- Doc ID Initialization을 정말 잘해야 제대로 작동할 것으로 보인다. 그런데 이 과정이 단순히 벡터DB에 임베딩 벡터를 넣는 것보다 훨씬 tricky하고 잘 만들기 어려워 보인다.
- 훈련할 때에도 어찌 되었던 Cross-Encoder에 의존하는 형태도 아쉽다. 물론 Cross-Encoder 대비 획기적으로 낮은 인퍼런스 cost를 검색에서 사용하겠지만, Cross-Encoder의 성능을 뛰어 넘을 수는 없을 것이다.
- 마지막으로 훈련 과정이 너무 복잡하다. 몇 번을 샘플링을 하는지 모르겠다. 그리고 하나라도 안하면 성능이 떨어지는 부분 역시 아쉽다.
- 결론적으로 "임베딩 모델만 가져다 쓰기"인 Dense Retrieval과 (튜닝을 안한다면), 그냥 인덱싱 후 계산 딸깍 하면 끝나는 BM25에 비해서 확실히 복잡하다.
- 근데 Dense Retrieval에 이론적인 한계가 있고, 실제로도 임베딩 모델 성능 향상에 어려움을 겪고 있는 상황이다. BM25는 워낙 오래된 기술이고... (키워드 기반) 어쩌면 generative retrieval이 성능의 퀀텀 점프를 가져다주지 않을까?