RAG-DDR
- 원문
- ICLR 2025 Poster
Why DDR?
기존에는 Retrieval 모듈과 실제로 답변을 생성하는 Generation 모듈을 따로 최적화한다. 그런데 Retrieval 모듈만 최적화하면, Generation 모듈 (LLM)에서 이미 내부적으로 학습한 지식 (parametric knowledge)와 Retrieval 모듈에서 온 지식끼리 충돌이 발생할 수 있다. 이렇게 충돌이 발생하면 더 좋은 답변으로 이어지기 어렵다.
더불어 Generation 모듈만 튜닝하는 SFT 같은 경우에는 주어진 instruction-tuning 데이터셋의 대답 양식에 제한되고 (오버피팅되고), 다양한 passage들이 오는 RAG와 같은 것에 대응하기 힘들다.
그래서 DDR은 DPO를 이용해 Retrieval과 Generation 모듈 모두를 훈련한다. (RAG의 처음부터 끝까지 훈련시킬 수 있다). 리워드는 RAG의 각 단계에서 리워드를 모아, 전체 시스템을 향상시키는 방향으로 학습이 진행된다.
DDR
기본적으로 RAG 시스템의 Markov Process와 유사하게, 처음에 들어온 쿼리부터 document를 retrieve하고, 그 결과를 다음 모듈들로 넘겨가면서 최종적으로 답변을 내놓게 된다. 어떠한 일련의 과정이라고 볼 수 있다.
물론 Modular RAG 등에서는 여러 모듈들이 반복적으로 사용되기도 하는데, 이것도 하나의 인퍼런스를 생각해서 펼쳐보면 일련의 Markov Process라고 할 수 있겠다.

이런 식으로 여러 모듈들을 거쳐서 최종적인 결과가 나오게 되는 것이 통상적인 RAG 구조이다.
그러면 중간의 각 모듈들에 있어서 리워드를 어떻게 줄 것인가? 다양한 방법이 있겠지만 DDR은 아래와 같이 리워드를 준다.
DDR에서의 리워드
위의 RAG 구조에서, 리랭커의 리워드를 DDR 방식으로 구해보자.
- 리랭커에서 리랭킹을 수행한 후, 재정렬된 문서를 output으로 내보낸다.
- 만약 하이퍼 파라미터 조정, 리랭커 종류 바꾸기 등 리랭커를 최적화할 수 있다면, 여러 output들을 내보낼 수 있다.
- 그 재정렬된 문서들을 활용해서, 그 뒤의 모듈들을 차례대로 실행한다 (필터 -> compressor -> LLM)
- 리랭커의 여러 output들에 대해 각각 실행될 것이다.
- 마지막으로 나온 LLM의 답변을 평가한다.
- LLM 답변의 평가 결과가 곧 리랭커의 리워드가 된다.
즉, 해당 모듈의 리워드는 해당 모듈의 결과를 다음 모듈들에 넣어 최종 결과의 평가 값이 곧 리워드가 된다.
일반화하면 다음과 같다.
모듈
그러면
DDR의 최적화
최적화를 위해서는 DPO를 활용한다. 이를 활용한 loss 함수를 보면 다음과 같다.
DPO 손실 함수와 사실상 같다는 것을 쉽게 알 수 있다.
어떻게 적용하는가?
1. Knowledge Refinement 모듈 훈련
여기서는 우리가 흔히 말하는 Retrieval 모듈 (VectorDB 등)에 대한 훈련은 진행하지 않고, LLM 에이전트 기반 모듈들에 대한 튜닝만 진행된다.
이 Knowledge Refinement 모듈 (이하 KR 모듈)은 LLM 기반의 passage reranker라고 보면 된다.
이 KR 모듈은 만약 쿼리와 단락이 관련있다면 YES, 관련이 없다면 NO를 내뱉도록 한다.
이제 여러 단락들에 대하여 모두 리워드를 계산한다. (모두 관련 있다고 가정하고, 다음 모듈들을 사용해 대답을 생성한 후 평가한다.)
여러 단락 중에 가장 리워드가 높은 것을 positive sample (
2. Generation 모듈 훈련
실제로 답변을 생성하는 LLM을 말한다. 이것을 어떻게 훈련할까?
첫 번째 답변 샘플으로는 KR 모듈까지 통과해서 필터링 된 단락들을 쿼리와 함께 넣어 답변을 생성한다. 두 번째로는 단락 없이 쿼리만 넣어 답변을 생성한다.
이제 두 답변에 대하여 리워드를 계산하고, 더 높은 리워드가 positive sample이 되고, 낮은 샘플이 negative sample이 된다.
이 뜻은, 만약 retrieve된 단락을 아예 이용하지 않는 경우가 더 높은 리워드를 얻는 경우, 아예 이용하지 않도록 훈련이 된다는 뜻이다. 이를 통해서, LLM의 parametric 지식과 retrieve가 된 단락의 지식 간에 충돌이 일어나는 현상을 줄일 수 있다.
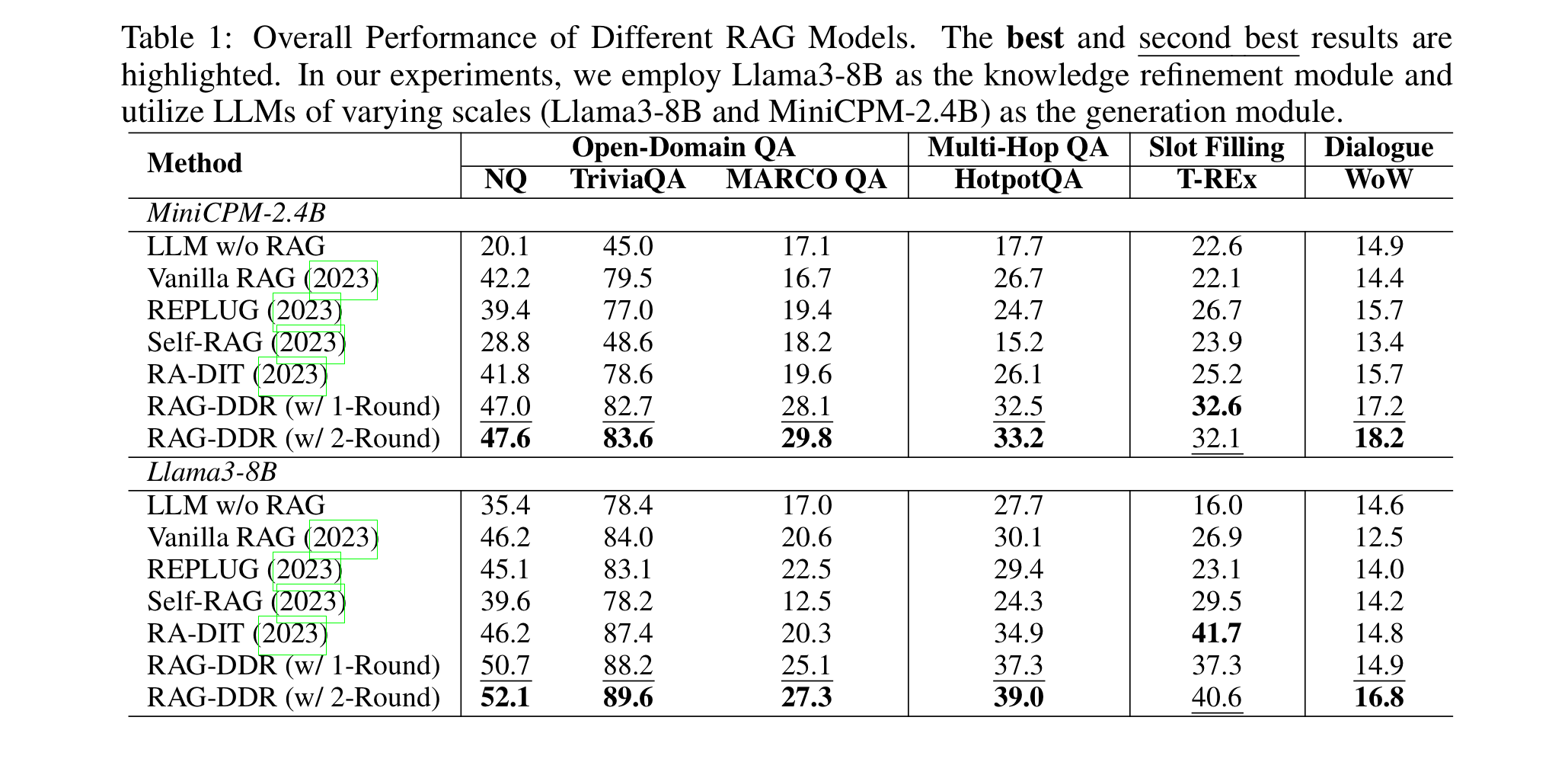
실험 결과
- 데이터셋
- MS MARCO 2.1 => 시험용
- 훈련용 => NQ, MARCO QA, TriviaQA, HotpotQA, WoW (Wikipedia of Wizard)
- 평가 : Rouge-L, F1, Accuracy
- 임베딩 모델 : bge-large
- LLM : Minicpm-2.4B-sft, Llama3-8B-Instruct
- 베이스라인
- 그냥 LLM (RAG 없음)
- 바닐라 RAG
- REPLUG : 여러 단락 조합들로부터의 output 확률들을 ensemble
- Self-RAG : LLM이 필요에 따라 문서를 retrieve 하도록 훈련
- RA-DIT : instruction-tuning 방법으로 RAG를 최적화