Promptriever
- 논문 링크
- ICLR 2025 Poster
논문의 아이디어
- LLM은 여러 프롬프트를 이용하여 LLM에게 다양한 task를 시키거나 명령을 수행하게 할 수 있다. 프롬프트 엔지니어링이 가능하다는 것이 현대 LLM의 발전에 큰 영향을 미쳤다!
- 그런데, retriever에 프롬프트 엔지니어링을 하는 것은 불가능할까? 만약 retrieval을 수행할 때에 단순히 사용자의 질문 쿼리만 넣는 것이 아닌, 프롬프트 엔지니어링을 통해 특정 조건에 맞는 원하는 문서만 불러올 수 있다면 너무 좋지 않을까?
- 더욱 나아가, LLM에 프롬프트 엔지니어링을 하는 것과 마찬가지로 retriever도 쿼리마다 다른 프롬프트를 적용해, 다양한 상황에 더 높은 정확도로 문서를 검색할 수 있지 않을까?
논문의 해결 방법
- MS MARCO 데이터셋을 기반으로, LLM을 사용해 각 쿼리와 단락에 맞춤화된 프롬프트 (instruction)을 생성했다.
- 특별하게, 쿼리마다 제각각 다양한 프롬프트를 생성하기 위해서 노력했다.
- 이에 더하여, 기존 쿼리와는 연관이 있지만 프롬프트와 함께 하면 연관이 없어지는, instruction-negative 단락들을 생성했다.
- 이 새로운 데이터셋으로 기존 Bi-encoder (BERT와 같은) 기반 임베딩 모델을 훈련시켰다!
결과 요약
- 이렇게 훈련한 임베딩 모델은, 경쟁 모델에 비해 더 높은 성능을 나타냈으며, 리랭커와 같은 Cross-Encoder 기반 모델에 비해서도 유사한 성능을 보여주었다. (Cross-Encoder 모델은 컴퓨팅 속도가 매우 느리다)
- **retriever에 프롬프트 엔지니어링으로 전체적인 retrieval 성능이 높아지는 것을 보았다! **
Query Capabilites of Retrievers
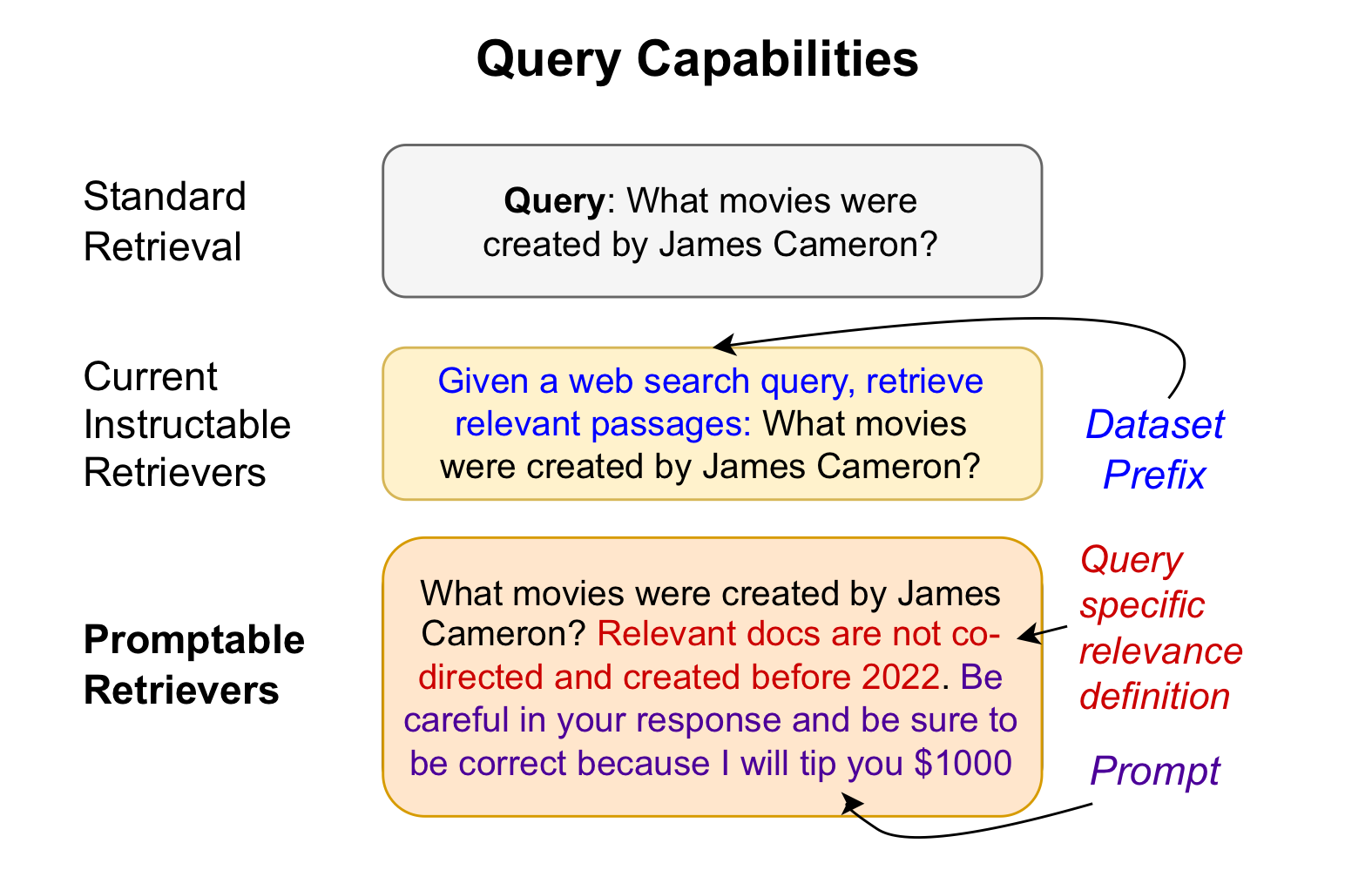
- Standard Retrieval - 우리가 떠올리는 간단한 retrieval 방식이다. 단지 유저의 쿼리만을 사용하여 임베딩 벡터 유사도 검색을 수행한다.
- Instructable Retrievers - 이 연구 이전에도 단순한 query 뿐 아니라, 특정 instruction을 추가해서 훈련을 진행하고, 이런 instruction을 넣어서 retrieve를 수행할 수 있는 retriever는 존재하였다.
그런데 이런 경우, 보통 query-specific하지는 않았고, 전체 데이터셋에 대한 instruction이 들어가는 형식이었다. - Promptable Retrievers - 이 연구에서 제안하는 형태이다. 본래 Instruction과는 다르게, 쿼리에 따른 지시를 추가할 수 있다. 보통 이는 질문에 대한 조건을 추가하는 식이다.
추가로, "잘 검색해오면 팁을 주겠어"와 같은 프롬프트를 추가해서 특정 역할을 수행하게 하거나 성능 향상을 노려볼 수 있다.
훈련 데이터셋 생성
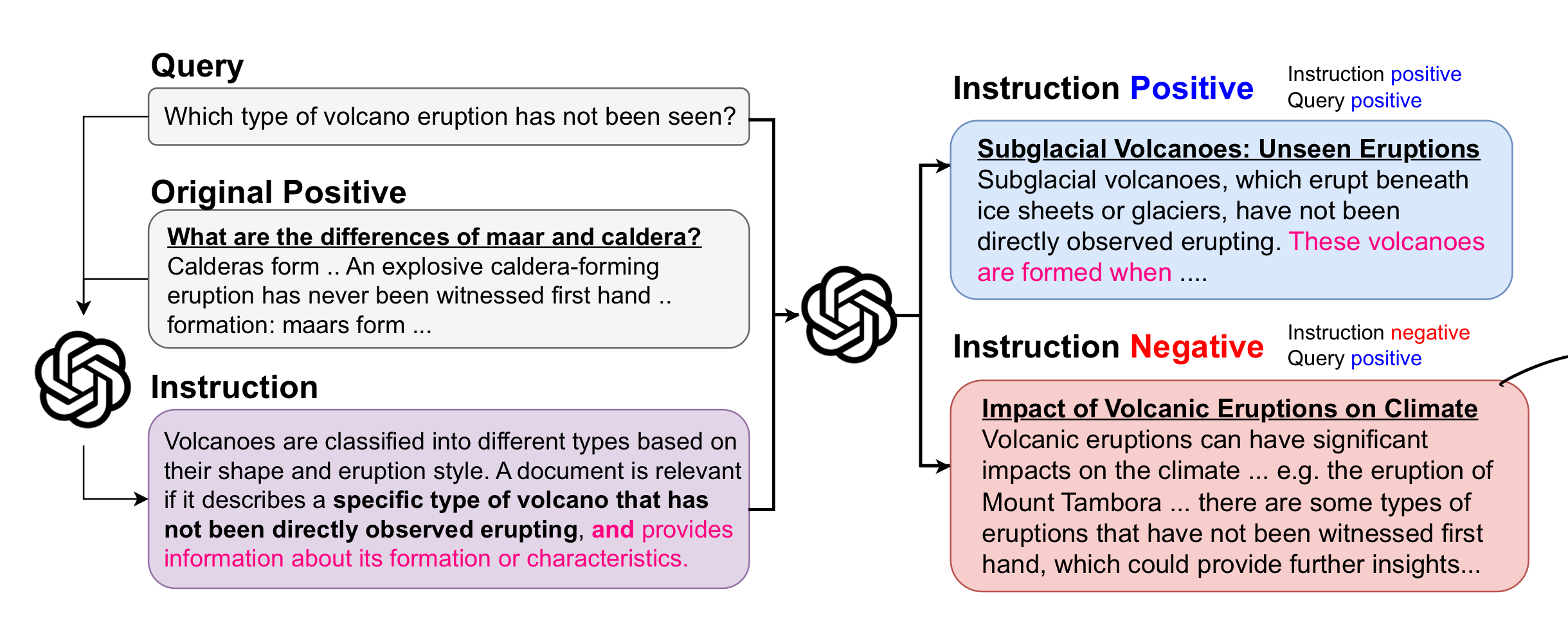
두 가지의 파트로 나눠진다.
첫 째로, 주어진 쿼리와 단락으로부터 Instruction을 생성하는 부분
두번 째로, instruction-negative 단락을 생성하는 부분
1. Instruction 생성
기본적으로, 쿼리와 그 쿼리와 관련된 단락을 제공하고 Instruction을 생성하도록 하였다.
이 때, 단순한 Instruction이 아닌, 특정 조건을 추가하여 단 하나의 positive 단락만 관련이 있도록 하는 식으로 Instruction을 생성하도록 하였다. 그렇게 하면 어떤 조건을 제시하는 Instruction을 주로 생성하게 된다.
다양한 결과를 내기 위하여, instruction의 길이와 스타일을 여러개로 지정하여 다양한 instruction을 생성하도록 했다.
2. Instruction-negative 단락 생성
앞에서 언급했듯이, instruction-negative 단락이란 원래 쿼리와는 연관이 있는 단락이지만, 추가된 instruction에 의하여 관련이 없어진 단락이다. 즉, instruction이 제시한 조건에 부합하지 않아 관련이 사라진 단락이라 할 수 있겠다.
이러한 단락이 필요한 이유는, 이런 단락이 없다면 instruction이 추가되던 안 추가되던 정답을 맞추기 위해서는 그냥 query만 보면 그만이기 때문이다.
기존 corpus에서 이러한 instruction-negative 단락을 찾는 것은 힘들었기 때문에, gpt-4o 모델을 이용하여 그러한 단락을 생성하여 훈련 corpus에 포함시켰다. 이후 필터링 과정도 거쳤는데, 사람과 LLM의 필터링 실력이 유사하였다.
모델 훈련!
모델은 RepLLaMA - Fine-Tuning LLaMA for Multi-Stage Text Retrieval 논문의 RepLLaMA 훈련 방식을 똑같이 따라갔다. 정확한 비교를 위해 하이퍼파라미터도 똑같이 설정해서 훈련했다고 한다.
단지 데이터만 위에서 생성한 데이터를 쓴것이다.
간단하게, query마다 다른 instruction을 포함해 훈련했다~ 가 되겠다.
논문에서는, 이렇게 데이터를 구성해서, backbone LLM의 instruction을 따르는 능력을 유지하면서 retriever용으로 훈련시킬 수 있었다고 한다.
실험 결과
Instruction을 따라야 하는 retrieval 태스크
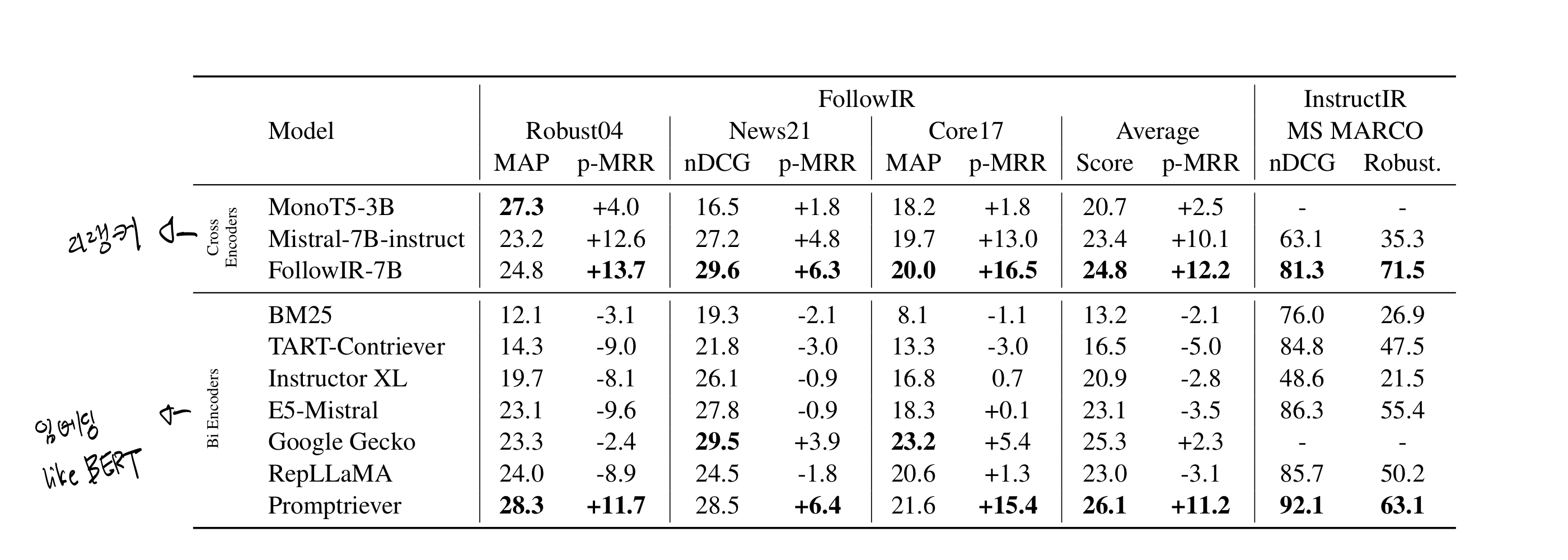
일반 retrieval 태스크
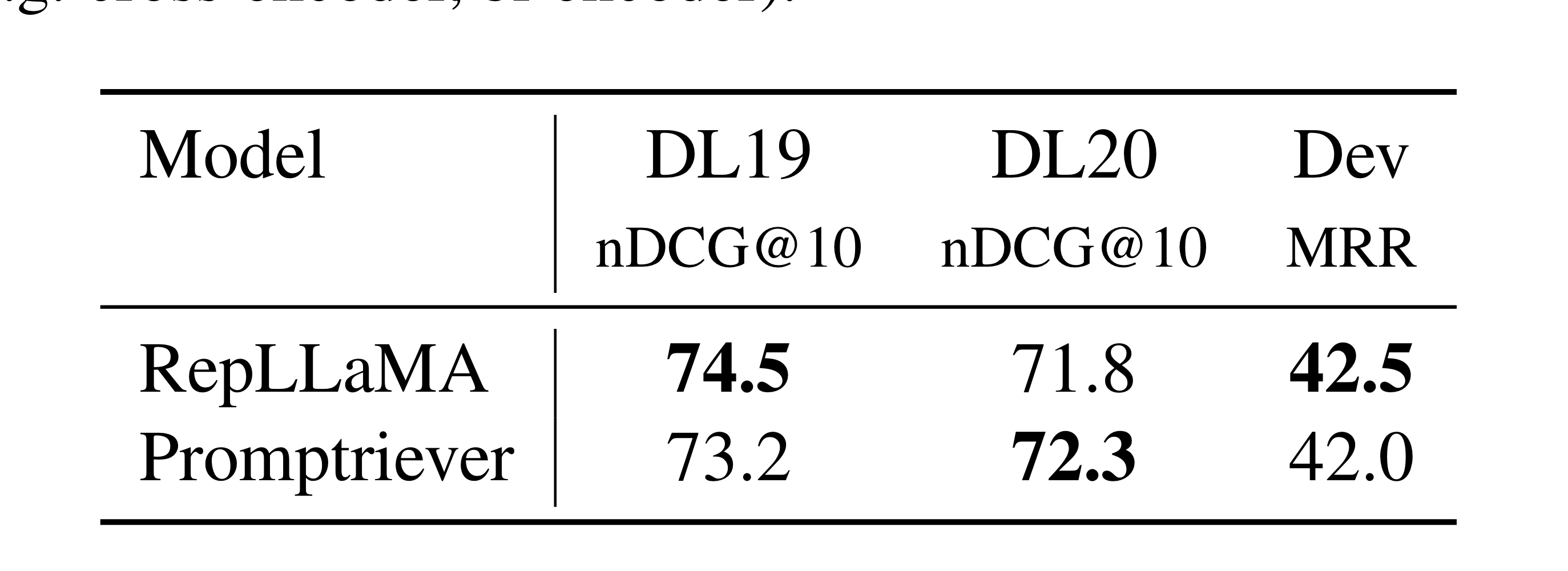
프롬프트 엔지니어링을 사용한 경우
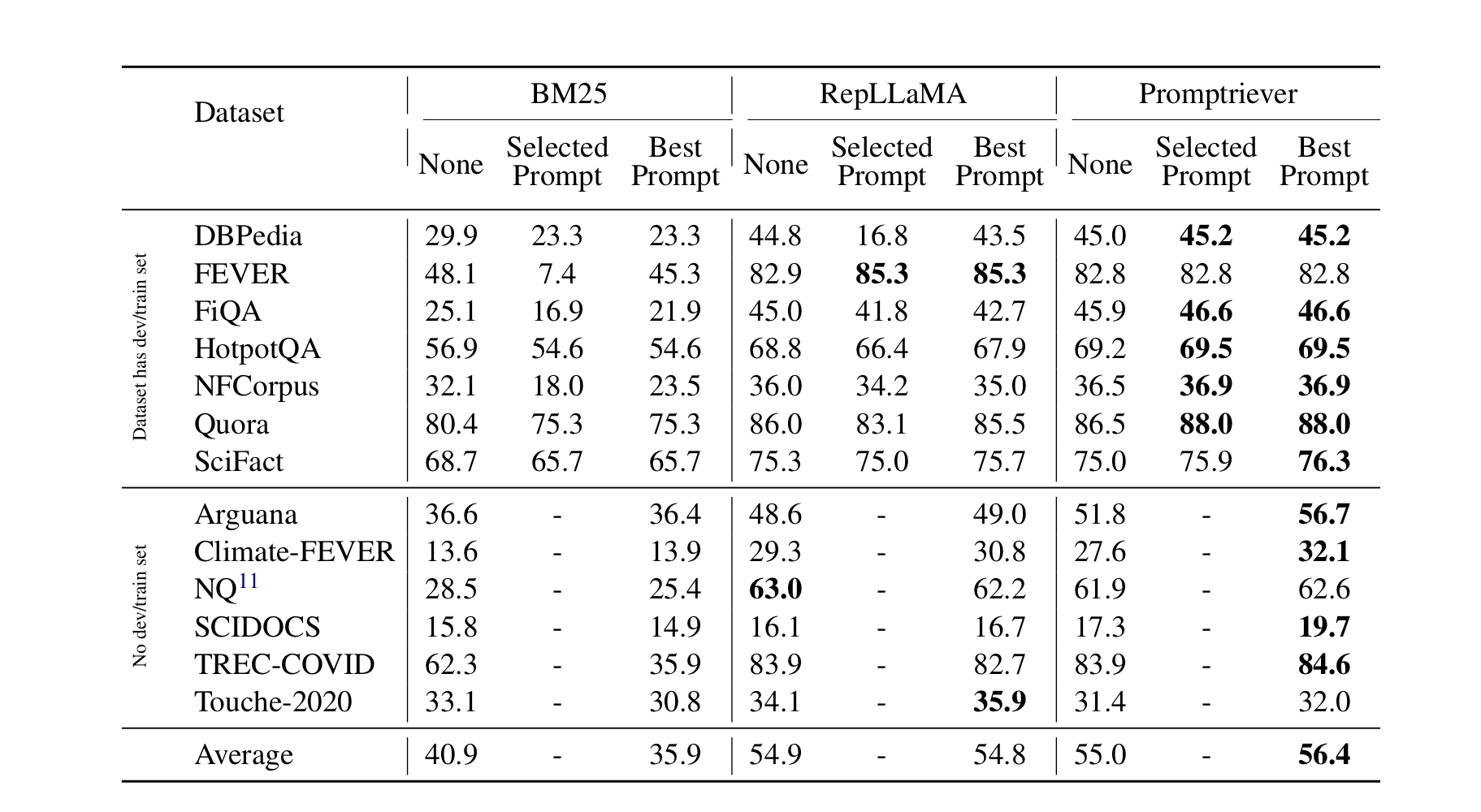
BM25와 RepLLaMA에서는 프롬프트를 사용하자 오히려 평균 성능이 떨어졌다. 반면에 본 연구의 모델은 성능이 +1.4퍼센트 포인트 올라간 것을 볼 수 있다.