PriorGrad
- 논문
- ICLR 2022 Poster
배경 지식
논문의 아이디어
원래 Diffusion Model (DDPM)에서 Forward Process를 진행할때, 결국 어떠한 형태의 노이즈가 되는지 기억나는가? 그렇다,
근데 Latent Diffusion Model (LDM)과 같은 condition generation을 할 때에, 아무 노이즈를 쓰는 것이 아니라, condition의 데이터에 특성을 반영한 노이즈부터 시작하면 안될까? 그렇게 하면 디퓨젼 모델을 효율적으로 학습 및 인퍼런스 할 수 있지 않을까?
이것이 이 논문의 아이디어다.
참고로 forward process의 끝이자 reverse process의 시작인 노이즈
어떻게 할까?
먼저 DDPM의 훈련 과정과 인퍼런스 과정을 다시 복기하자.

DDPM Train 과정
- 데이터셋에서 데이터를 샘플링한다.
- 1~
중에 특정 step을 랜덤으로 고른다. (노이즈 스케줄이 정해져있기 때문에 순차적이 아닌 마구잡이로 학습할 수 있다) 를 따르는 노이즈를 샘플링한다. - 이제
을 계산하고 그 그라디언트를 이용해 모델 를 업데이트한다.
DDPM 인퍼런스 과정
- 생성을 시작할 노이즈를
에서 샘플링한다. - 이제
부터 순차적으로 모델 를 이용해서 디노이즈 한다. - 마지막으로 생성 결과
를 리턴한다.
증명을 생략하면 쉽다(???)
아래는 PriorGrad의 훈련 및 인퍼런스 과정이다.

PriorGrad 훈련 과정
- 데이터셋에서 데이터를 샘플링한다.
- 1~
중에 특정 step을 랜덤으로 고른다. 를 따르는 노이즈를 샘플링한다. - 이제
를 계산한다. 이 때, 공분산 행렬의 역행렬 를 이용한 마할라노비스 거리이다. - 그라디언트를 이용해 모델
를 업데이트한다.
PriorGrad 인퍼런스 과정
- 생성을 시작할 노이즈를
에서 샘플링한다. - 이제
부터 순차적으로 모델 를 이용해서 디노이즈 한다. - 마지막으로 생성 결과
를 리턴한다. 이 때 prior의 평균 를 더해준다.
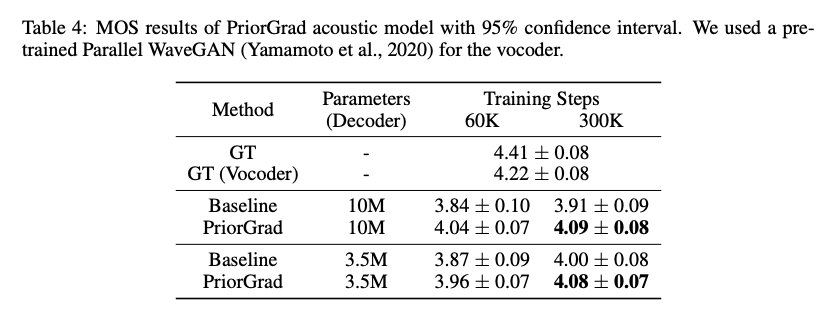
결과
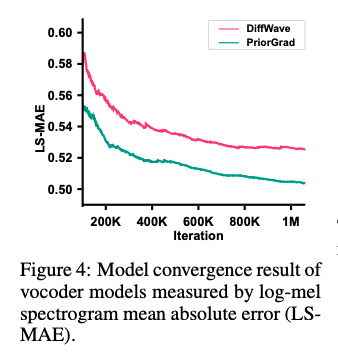
Vocoder에서의 성능
Diffwave와 비교했더니, 학습 속도도 빠르고 결과도 더 좋았다.

Acoustic Model에서의 성능
FastSpeech 2와 비교했더니 성능이 더 좋았다.