HuBERT
HuBERT의 목적
HuBERT는 마치 자연어에서의 BERT와 같은 인코더를 오디오에서 만들기 위함이다.
다른 말로 말하자면, 오디오를 어떠한 의미있는 representation으로 만들고자 하는 것이다.
이러한 의미 있는 representation을 만들 수 있다면, 그것을 어떠한 downstream task에 쓸 수 있을 것이다. 마치 BERT처럼 말이다!
예를 들어서, HuBERT를 거친 다음 MLP 레이어를 붙여서 classification에 쓸 수도 있고, 오디오 음성에서 글자를 추출하는 STT 모델로도 쓸 수 있을 것이다. BERT를 여러 태스크에 사용하는 만큼 HuBERT 역시 여러 태스크에 사용할 수 있다.
HuBERT의 목적을 정리하자면 “오디오를 마치 자연어처럼 처리해서, BERT와 같은 모델을 오디오에서도 만들어보자”라고 생각한다. 이 목적을 머리에 두고 논문을 따라가보자.
Introduction - 오디오는 왜 어려울까?
“오디오계의 BERT”를 만든다고 했을 때, 어떠한 점이 어려울까?
마치 viT에서 이미지의 inductive bias에 주목했던 것처럼, 오디오도 그 포맷의 특성상 어려운 부분이 존재한다.
논문은 그 어려움을 크게 세 가지로 정리한다.
- 하나의 인풋 음성에 여러개의 소리 유닛들이 존재한다.
- pre-training 단계에서 각 소리 유닛에 대한 lexicon (일종의 사전, dictionary)가 없다.
- 각 소리 유닛들을 나누는 기준이 매우 모호하다.
세 가지 한계점을 조금만 자세히 알아보자.
1. 하나의 인풋 음성에 여러개의 소리 유닛들이 존재한다.
여기서 말하는 소리 유닛 (sound unit)이란 것이 무엇을 의미하는 것일까?
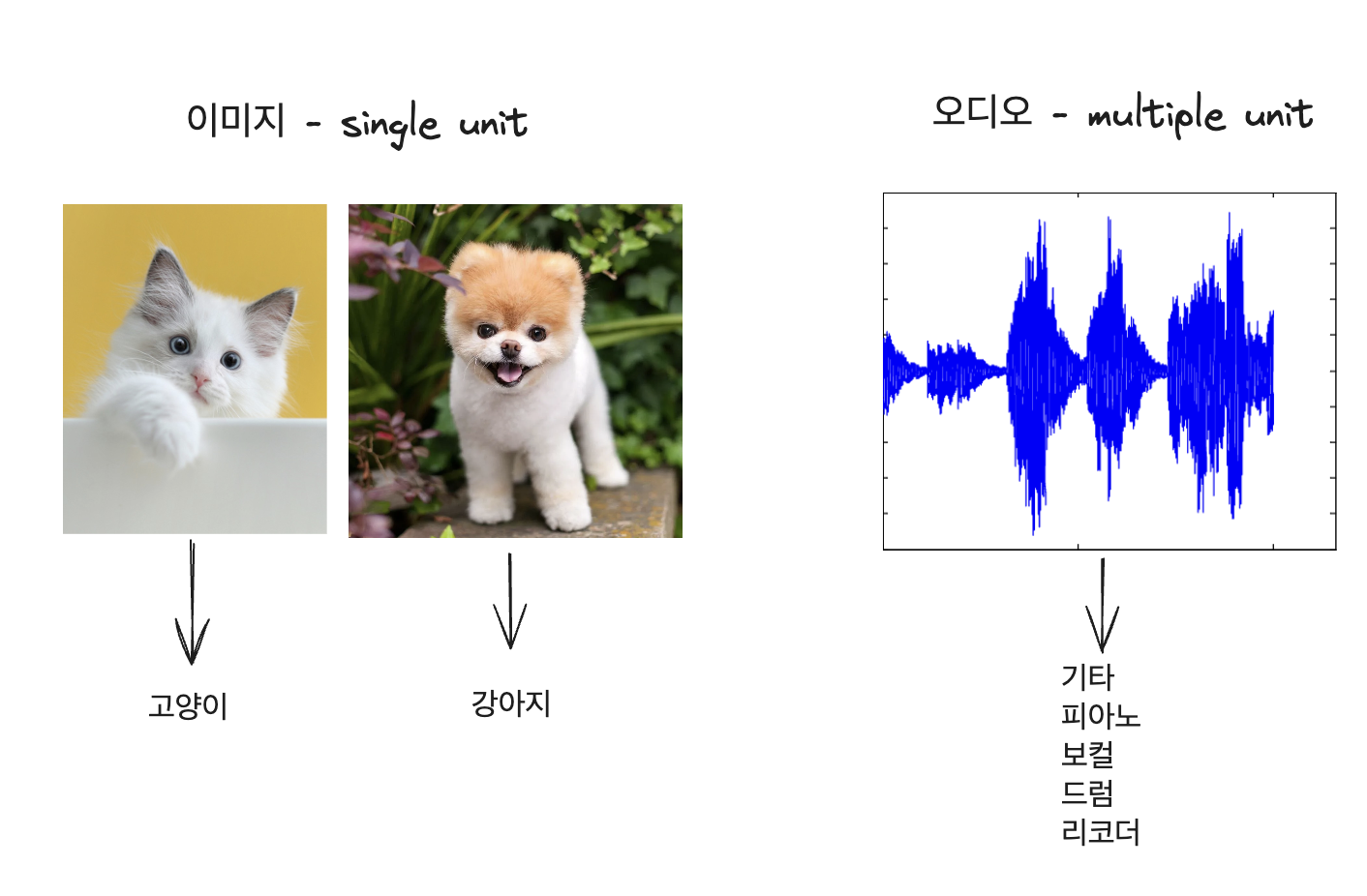
이해하기 쉽게 classification을 한다고 생각해 보자. 예를 들어서 이미지 분류를 할 때, 하나의 “unit”이란 것은 이 사진이 고양이인가 강아지인가를 의미하는 것이다.
viT를 이용해 이미지 분류를 위한 훈련을 한다고 생각해보면, 해당 이미지 내의 patch들이 어떤 것을 의미하는지 매우 명확하다. 그 사진은 “고양이” 혹은 “강아지” 사진이고, 사진은 대체로 그것을 가리키고 있다.
하지만, 오디오는 여러 유닛들이 섞여있다. 여러분들이 수업 시간에 녹음을 한다고 하면, 한 오디오 안에 “교수님의 목소리”와 “어떤 학생이 코를 훌쩍거림”, “키보드 타이핑 소리”, “출석 호명에 대답하는 학생의 대답 소리”등이 다양하게 혼재할 수 밖에 없다.
음악이라고 쳐도 기타, 피아노, 보컬, 드럼 등 여러 유닛에 해당하는 소리들이 마구 섞여 있다. 이런 상황에서 이미지와 같은 접근으로 훈련 방법을 가져갈 수는 없을 것이다.
2. pre-training 단계에서 각 소리 유닛에 대한 lexicon (일종의 사전, dictionary)가 없다.
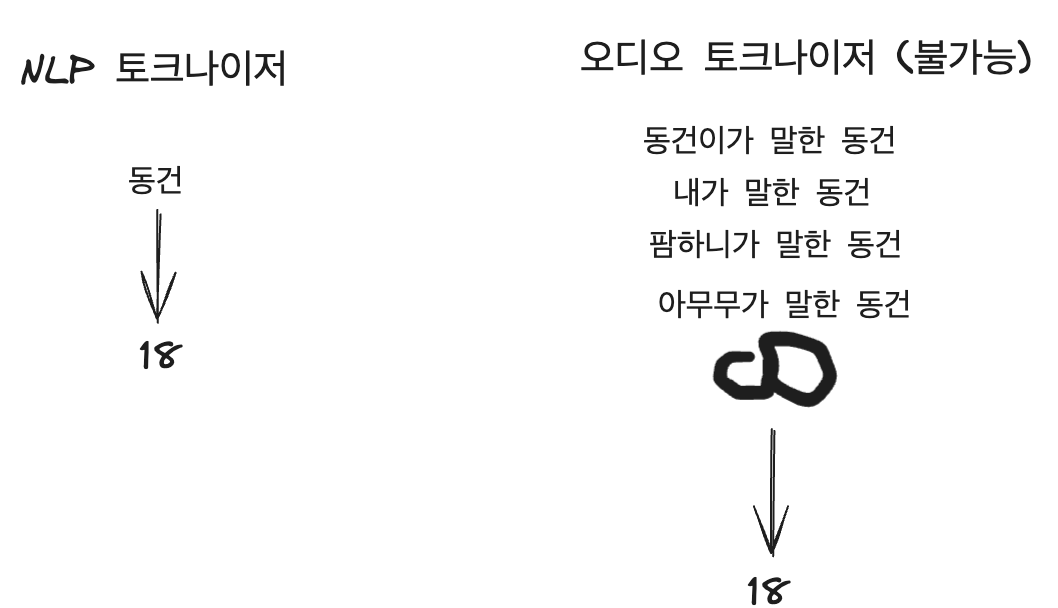
NLP(자연어)에는 tokenizer가 있다**.** 어떤 단어나 언어의 단위들을 특정 토큰(숫자)로 변환시키는 일종의 사전이라고 볼 수 있다. 예를 들면, “동건”이라는 단어는 18으로, “하베르츠”라는 단어는 19로 변환하기로 약속한다면 그것은 일종의 토크나이저이다. 이 토크나이저가 있기에, 자연어를 특정한 숫자 시퀀스로 표현해서 훈련하기가 매우 쉬워진다. 기계도 이해할 수 있어 지는 것이다.
그러나 오디오는 어떠한가? 오디오에서 토크나이저를 만드려고 한다면, 큰 문제에 부딪힌다.
“동건”이라는 단어에 대해 오디오 토크나이저를 만든다고 했을 때, “동건”은 하나의 음성으로 표현될 수 없다. 동건이가 말한 “동건”, 필자가 말한 “동건”, 팜하니가 말한 “동건”은 모두 각기 다른 음성으로 표현된다. 다른 음성이지만 모두 같은 동건이다. 문제는 “동건”을 말할 수 있는 방법은 무한하다. 그렇기에, NLP와 같은 방식 (토크나이저 사용)을 사용할 수 없다.
3. 각 소리 유닛들을 나누는 기준이 매우 모호하다.
STT를 만드려고 한다고 생각해보자. 토크나이저는 못만드니, 일단 음성을 음소 단위로 나누는 것부터 시작하자.
그런데, 음성은 연속적이고, 각 단어의 경계가 명확하지 않다.
https://www.youtube.com/watch?v=u_ziPVJyO1o
이 노래에서 성기훈의 말을 음소 별로 나누어보려고 한다.
“얼음~”을 나눈다고 했을 때, 몇 초부터 몇 초까지 끊어야 할까? 직관적으로는 누구든지 분리할 수 있는데, 그 위치는 자르는 사람마다 조금씩 다를 것이다.
누군가는 “얼음”이라고, 누군가는 “얼음~ ~ ~”, 누군가는 “얼음~”과 같이 끊을 것이다. 그리고 만약에 “얼음~”이라고 다 같이 끊었다 할지라도, 실제로 다 똑같지는 않다. 몇 ms씩 무조건 차이가 나기 마련이다.
자연어였다면 “얼음”으로 아주 쉽게 나눌 수 있는 일이다.
이렇게 오디오에는 크게 세 가지의 어려운 점이 존재한다. 이 세 가지 어려움을 어떻게 극복하고 HuBERT를 완성할 수 있었는지 생각해보며, HuBERT에 대해 더 자세히 알아보자.
Introduction - supervised, semi-supervised (PL), self-supervised
각각의 training 방법에 대해서 한 번만 짚고 넘어가자.
Supervised Learning
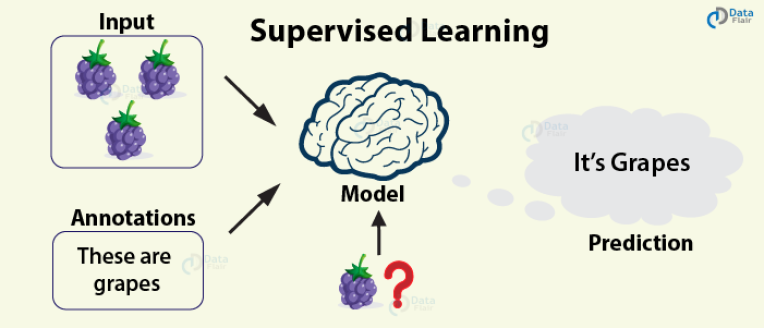
가장 기본적이다. 레이블된 데이터를 가지고 학습한다. EASY
Semi-supervised Learning
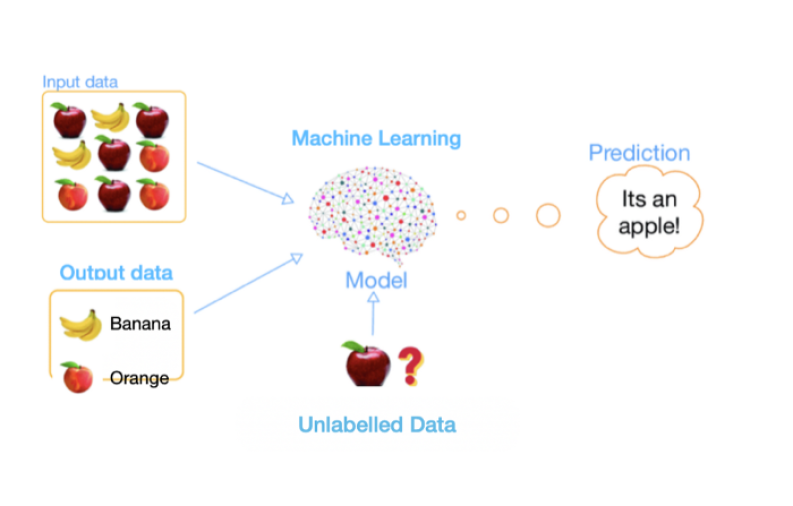
일부만 레이블이 된 데이터를 가지고 학습한다.
어떻게 레이블이 없는 데이터를 포함해서 학습할까? 주로 Pseudo 라벨링 (PL)을 많이 이용한다.
먼저, 레이블된 데이터를 이용해서 최초의 모델을 만들고, 그 모델을 이용해 라벨링 되지 않았던 데이터를 예측한다. 그리고, 그 예측된 데이터를 포함하여 모델을 다시 학습한다.
이 과정을 여러 차례 반복할 수도 있다. 즉, pseudo-label (가짜 레이블)을 만들어서 학습에 활용하는 것이다.
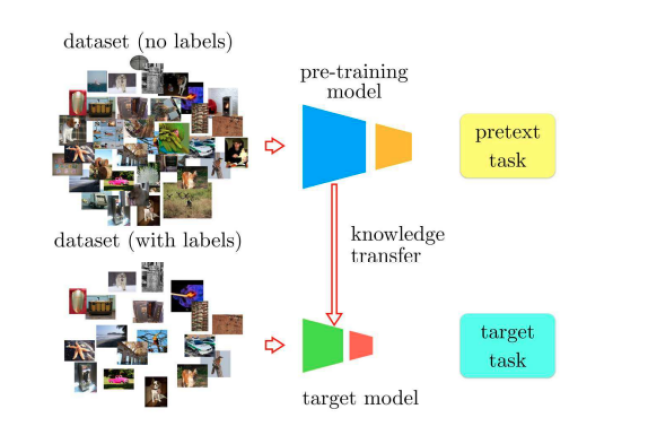
Self-Supervised Learning
앞서 설명한 PL에는 두 가지 주요한 문제점이 있다.
- 레이블된 데이터가 만든 최초 모델의 성능에 크게 의존한다. 만약 레이블된 데이터가 충분치 않으면 pseudo-label의 성능이 낮고, 열심히 iteration해도 성능 향상이 힘들 수 있다.
- 하나의 태스크에만 맞춰서 훈련하게 된다. 여러 downstream task에 대응이 불가능하다.
이런 문제점을 해결할 수 있는 것이 self-supervised learning이다. self-supervised learning은 두 단계로 이루어진다.
- pre-training 단계 : 레이블이 없는 다량의 데이터를 사용해서 훈련한다. 자연어의 “masked prediction”을 생각하면 좋다
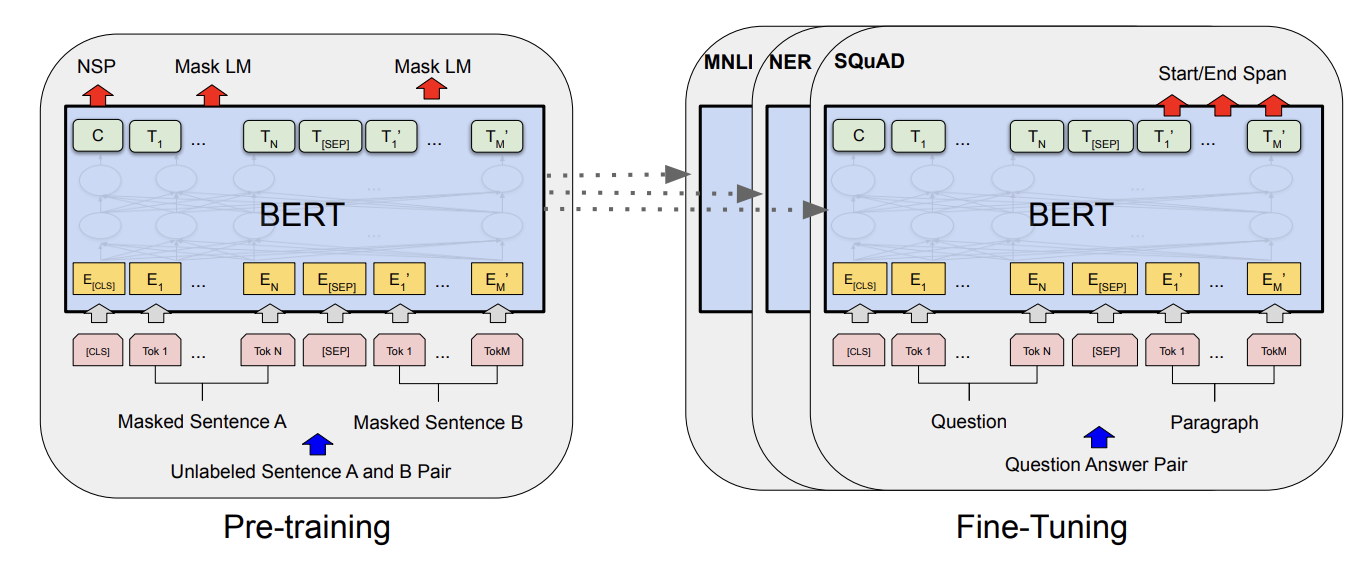
- fine-tuning 단계 : 각 downstream task에 알맞은 형태의 “레이블된” 데이터를 사용해서 훈련한다. BERT를 각 태스크에 맞춰 fine-tuning하는 것을 생각하면 좋다. (BERT가 전형적인 self-supervised learning의 예시라고 볼 수 있겠다)
HuBERT를 만들어 봅시다
이제 오디오계의 BERT인 HuBERT를 만들어보자. HuBERT를 통해 앞서 설명한 3가지의 문제점을 극복하면서, self-supervised learning을 사용해 기존 PL의 문제점도 해결할 수 있을 것이다.
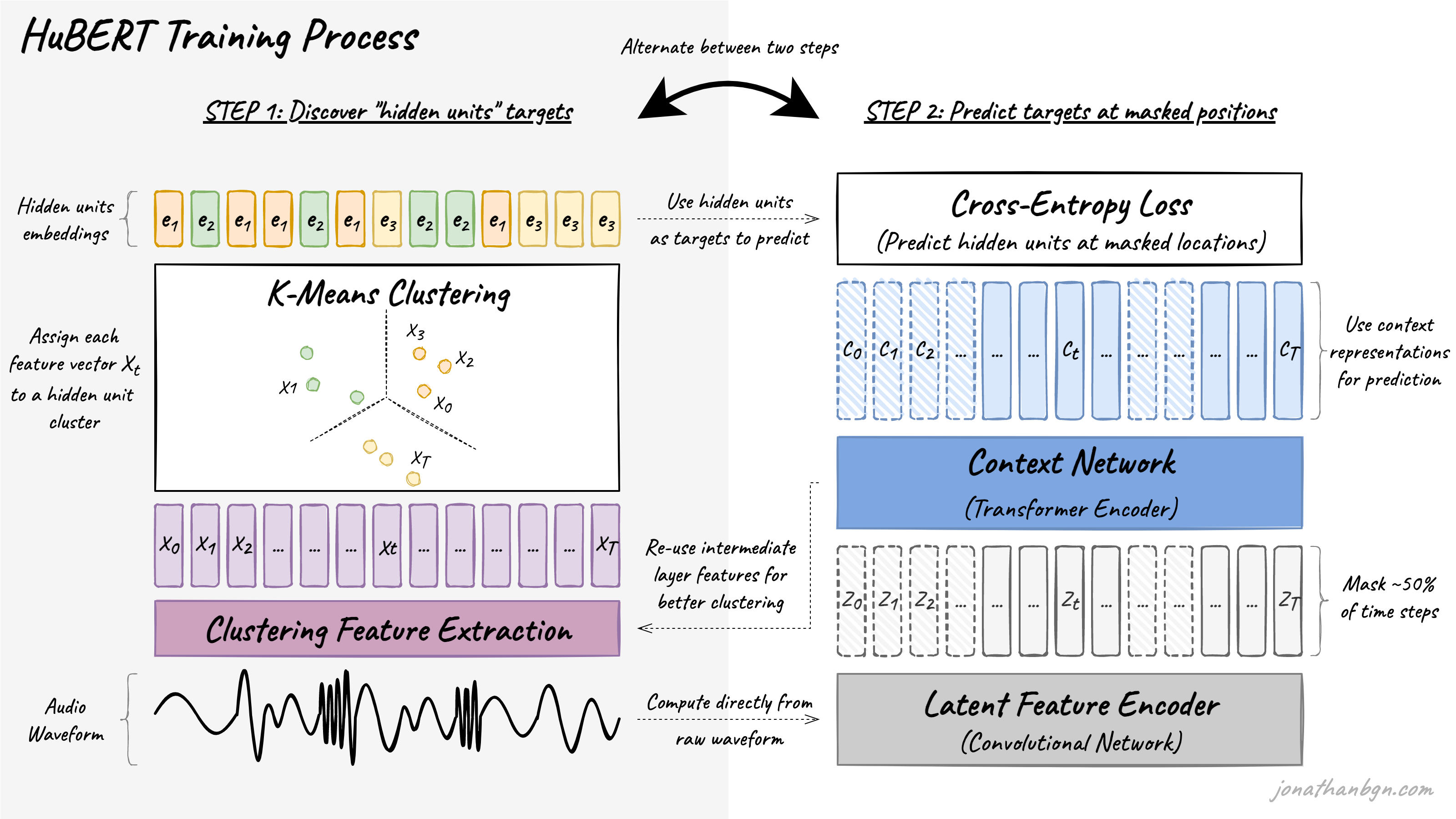
전체적인 HuBERT의 훈련 과정이다. 이것만 보면 잘 모르겠으니, 두 단계로 나누어 자세히 설명해보겠다.
1. 클러스터링을 통하여 “Hidden Unit” 찾기
앞에서 “unit”은 분류할 클래스 같은 것이라고 했다. 이해를 돕기 위해 STT (speech-to-text) 태스크를 한다고 생각해보자. unit은 각각의 글자가 되겠고, latent space에서 각 글자를 의미한다고 할 수 있는 어떤 representation을 “Hidden unit”이라고 할 수 있겠다.
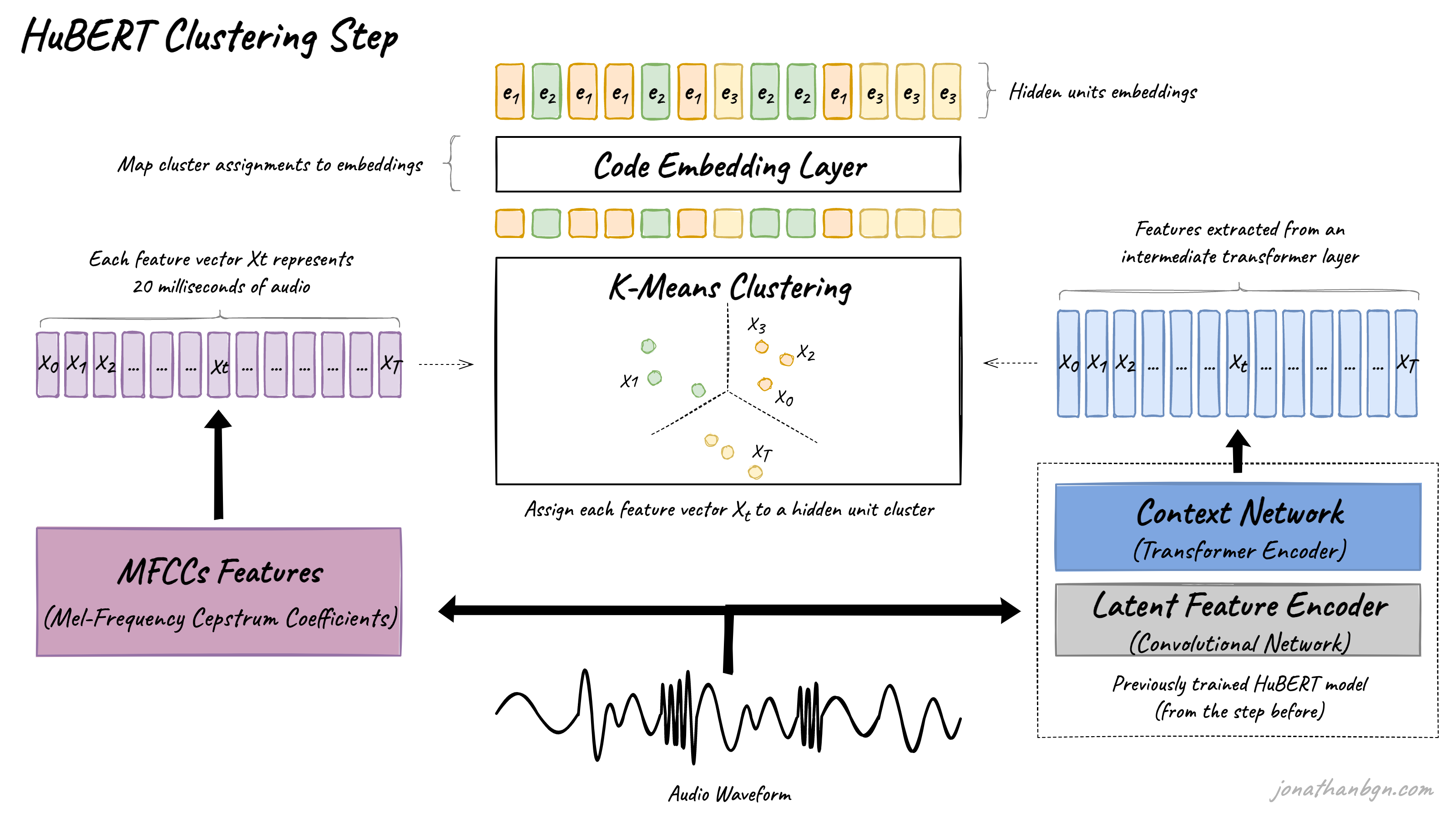
이제 “Hidden Unit”을 찾기 위해서 clustering을 수행할 것이다.
앞서서 오디오는 lexicon (일종의 사전 혹은 토크나이저)도 없고, 각 unit 간의 경계도 모호하다고 했다. 그래서 마치 viT에서 이미지를 patch로 나누듯이 오디오도 특정 시간 단위 (프레임 단위)로 나누게 된다. 논문에서는 20ms 단위로 오디오를 나눴다.
“클러스터링”은 전형적인 unsupervised learning이고, label이 없는 상태에서 유사한 특성을 가진 것들끼리 묶어준다. 오디오를 20ms 단위로 나누고, clustering을 수행하면 각각의 클러스터가 어떤 글자를 의미하는 음성인지는 모르겠지만 얼추 비슷한 것들끼리 묶이게 될 것이다. 각각의 클러스터는 우리가 원하는 “Hidden Unit”이 되는 것이다.
구체적으로 클러스터링을 수행하는 과정을 살펴보자.
첫째로, MFCCs (Mel-Frequecy Cepstral Coefficients)를 수행하여 오디오를 20ms 단위로 자르고 각각을 어떤 Vector로 표현한다. MFCCs가 뭔지 아는 것은 중요하지 않고, 원본 음성 waveform에서 feature를 잘 찾아내는 잘 알려진 방법을 사용했다고 생각하면 편하다.
이렇게 나온 20ms의 오디오 프레임을 나타내는 벡터들을 k-means 알고리즘 등을 이용해 클러스터링을 한다. 그러면 자연스레 각 벡터들이 어떠한 클러스터로 변환되게 된다.
이후 “Code Embedding Layer”를 통과하면 벡터들을 각각의 “클러스터 임베딩”으로 바꾸게 된다. 레이어를 통과하면서 한 클러스터에 존재하는 여러 벡터들이 하나의 대표적인 클러스터 임베딩 벡터로 바뀌게 되는 것이다. 이는 마치 NLP에서 “한 토큰”이 “하나의 word 임베딩 벡터”를 나타내게 되는 것과 유사하다.
pre-training 과정에서 한 번만 클러스터링을 수행하는 것이 아닌, 두 번 혹은 세번 (논문에서는 아니지만 그 이상도?) 클러스터링을 진행한다. 두번째 부터는 MFCCs를 사용하는 것이 아니라, 훈련된 트랜스포머 인코더 모델의 layer를 그대로 가져와 feature vector로 사용한다. 2번째 단계에서 훈련할 트랜스포머 인코더가 맞다.
이렇게 여러 번 clustering을 거칠수록 당연히 클러스터링이 더 잘 일어나고, Hidden Unit들이 명확하게 분리될 것이다.
2. 1단계에서 분류된 unit 맞추기
2단계는 BERT랑 똑같다 (loss도 Cross Entropy로 같다!)
앞서 1단계에서 각 오디오 프레임들에 “Hidden Unit”, 즉 어떤 클러스터 (label)인지 라벨링이 된것이다. 물론 완벽하게 라벨링 된것이 아니기에, noisy target이라고 할 수 있겠다. 이 단계에서는 이러한 noisy target을 맞추려는 방향으로 트랜스포머를 훈련하게 되는 것이다.
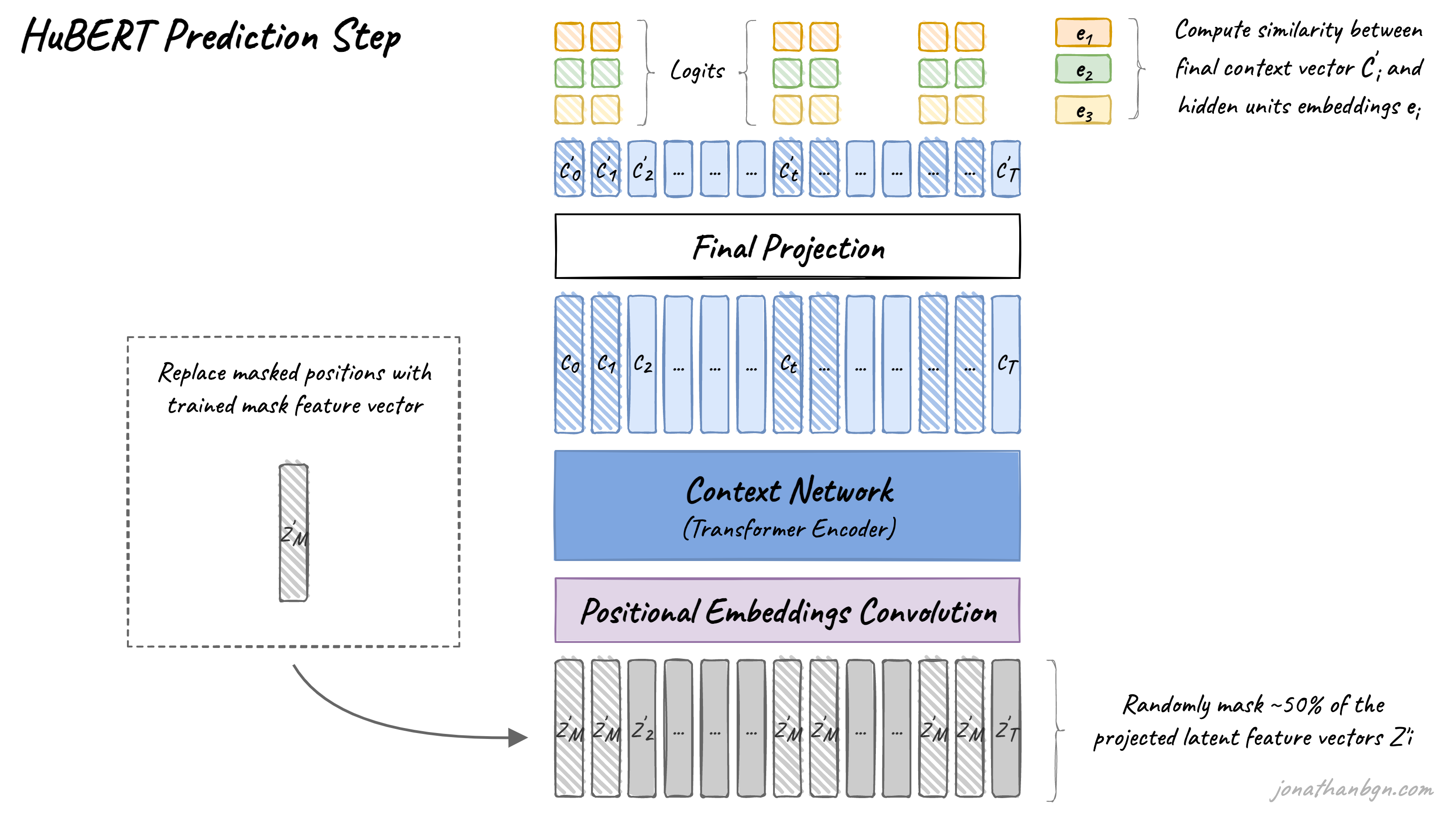
훈련 방법은 다음과 같다.
- 앞서서 나온 벡터들 중에서 랜덤으로 프레임을 마스킹 처리한다. 논문에서 마스킹은 p% 만큼의 프레임을 랜덤으로 선택하고, 그 주변으로 l개의 프레임을 마스킹했다.
- CNN Encoder를 통과한다. NLP에서의 positional encoding을 CNN으로 수행한다고 보면 된다. 이는 오디오의 locality를 반영하려는 것 같다.
- 이제 BERT와 같은 트랜스포머 인코더를 통과한다.
- BERT에서 나온 벡터를 projection layer에 넣어, 1단계에서 구한 cluster vector와 같은 차원으로 변환한다.
- 각 cluster vector와 최종 Projection layer를 거친 벡터와 cosine similarity를 계산하여, 가장 similarity가 높은 cluster를 prediction cluster로 선정한다.
- clustering 과정에서 예측한 프레임의 cluster와, 트랜스포머 인코더를 거친 후 예측한 cluster가 일치하는지 평가한다. 이 과정은 Cross Entropy loss로 계산되며, 해당 loss를 최적화하도록 훈련된다. (cluster를 정확하게 예측하고자 훈련된다)
-
Projection Layer가 필요한 이유?
BERT에서 나온 벡터는 BERT의 dimension일 것이다. (ex. 768) 하지만 cluster vector의 크기와 다르기 때문에, cosine similarity 연산을 위해서 projection layer를 이용한다.
해당 projection layer는 pre-training에서만 사용하고, fine-tuning을 진행할 때에 새로 학습하거나 softmax만을 적용할 수도 있다.
논문에서는 Cross Entropy loss를 마스킹된 프레임에 대해서만 계산하여 훈련을 진행했다. 연구진은 마스킹되지 않은 프레임에 대해서도 loss를 계산하여 학습을 진행해 보았는데, 마스킹된 프레임에 대해서만 loss를 적용했을 때 가장 높은 성능을 기록했다.
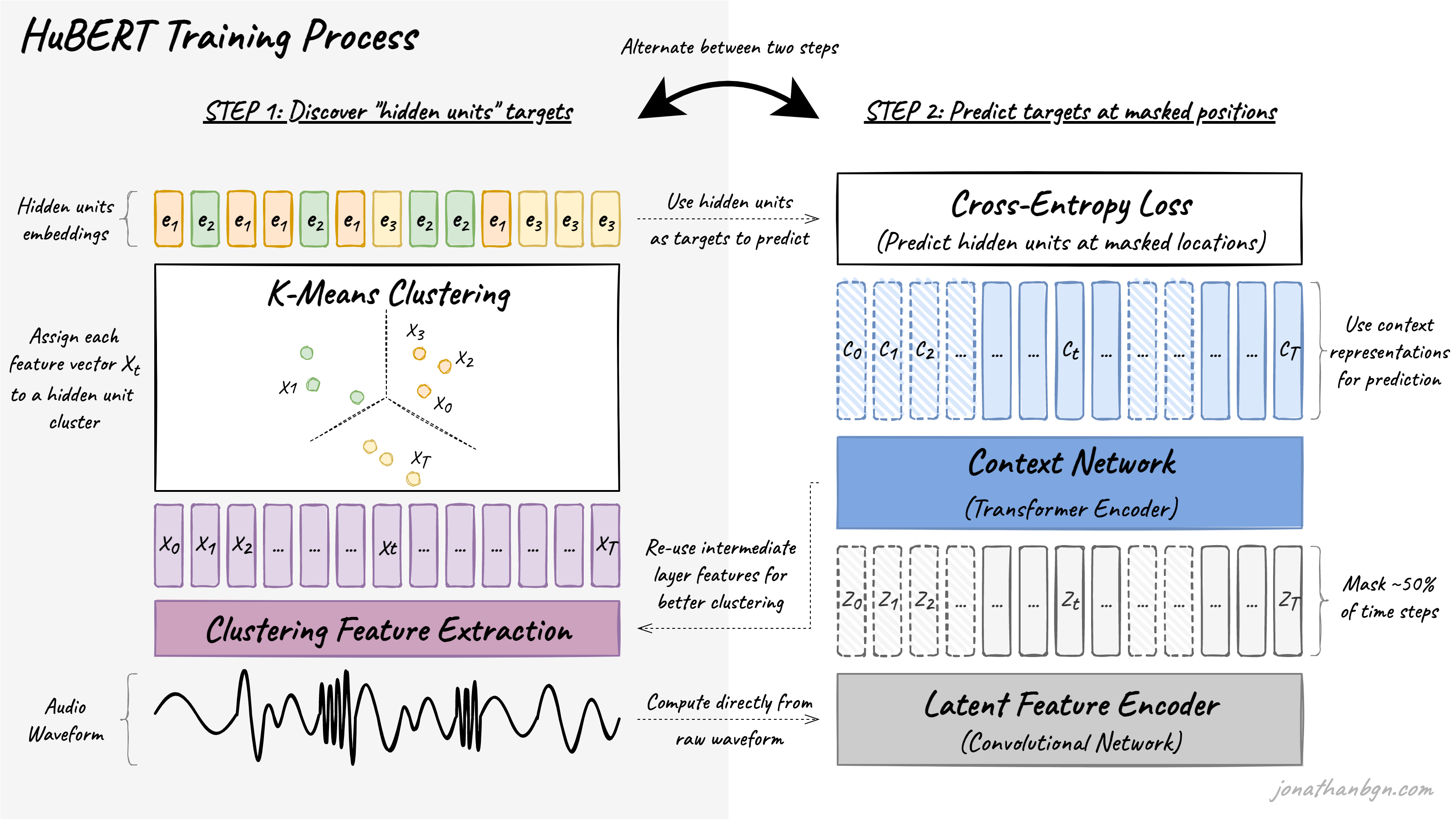
이제 다시 전체 학습 순서를 보며 HuBERT의 훈련 과정을 복기해보자.
self-supervised learning인 만큼 fine-tuning 단계가 존재하며, 앞서 언급했다시피 fine-tuning 과정에서는 마지막 projection layer를 초기화하고, CNN 인코더는 frozen 한다 (학습하지 않는다).
오디오의 문제를 HuBERT는 어떻게 극복했는가?
- 하나의 인풋 음성에 여러개의 소리 유닛들이 존재한다.
- 클러스터링을 하면, 하나의 sample에 대해서 클러스터의 개수 만큼의 유닛들을 포착할 수 있다.
- pre-training 단계에서 각 소리 유닛에 대한 lexicon (일종의 사전, dictionary)가 없다.
2. clustering과 code projection layer를 거치면 각 프레임이 각각의 cluster vector로 표현된다. 자연어처리에서 토크나이저를 사용하면, 같은 토큰이 같은 vector로 표현되는 것과 유사하다. - 각 소리 유닛들을 나누는 기준이 매우 모호하다.
- 20ms라는 작은 프레임으로 소리 유닛을 나누고, 클러스터링을 수행하면 자연스럽게 이웃 프레임들이 주로 하나의 클러스터로 묶이게 될 것이다. 더불어서, 훈련 과정에서 마스킹을 특정 span을 마스킹을 함으로써 유닛이 동적으로 나누어 지도록 유도한다고 생각할 수 있다.
- 더불어 CNN Encoder를 사용하며 이것도 학습되기 때문에, 모호한 유닛을 나누는 기준을 학습하고 있다고 볼 수 있겠다.
실험 결과
자세한 내용은 논문을 참고하자.
논문에서는 STT task에서 HuBERT가 기존 방법보다 더 좋은 성능을 낼 수 있었다고 실험적으로 증명하고 있다.
또한, 가장 큰 X-LARGE 모델은 1B개의 파라미터를 가지고 있다.