이 MoE 모델은 무료로 임베딩 해줍니다
- ICLR 2025 Oral
- 논문 원문
- 원 제목 : Your Mixture-of-Experts LLM is Secretly an Embedding Model for free
(당신의 MoE LLM은 몰래 무료로 임베딩 모델을 하고 있어요)
논문 요약
MoE 모델 내부에는 어떠한 expert (전문가)를 사용할 지를 결정하는 routing weight가 계산이 된다. 이 routing weight를 곧 임베딩 벡터로 이용할 수 있다!
거기에 LLM의 마지막 hidden state를 활용하는 기존의 방식과 가중합을 하면 성능이 더 좋아진다.
즉, 추가적인 훈련 과정 없이 MoE LLM 모델을 곧바로 효과적인 임베딩 모델로 활용할 수 있다.
Background
임베딩 모델의 학습
먼저 임베딩 모델이 어떤 것이고 왜 필요한지는 모두가 이해한다고 가정하겠다. 혹시나 임베딩 모델이 뭔지 모른다면 구글링 or LLM이 아주 친절하게 답해 줄 것이다.
기존 임베딩 모델은 대체로 InfoNCE와 같은 contrastive learning을 통하여 훈련되었다. 비슷한 문장 (positive sample)간의 similarity는 높이고, 의미가 판이한 문장 (negative samples)간의 similarity는 낮추는 방식으로 학습이 진행되었다. 보통의 경우 bge 임베딩 모델 같은 경우 BERT와 같은 모델을 기반으로 contrastive learning을 통해 임베딩 모델로 사용되어 왔다.
LLM을 임베딩 모델로 활용해보자
그 후, LLM이 나오면서 LLM 자체를 임베딩 모델로서 사용하려는 노력이 있어왔다. 당장 임베딩 모델 리더보드인 MTEB 벤치마크 페이지에 들어가 보시면, 상위권에 있는 모델 대부분이 미스트랄-7B와 같은 LLM을 기반으로 변형한 모델임을 쉽게 알 수 있다. 그런데 보통, 이런 임베딩 모델들은 LLM의 마지막 hidden state를 임베딩 벡터로 활용하면서 contrastive learning을 수행한다. 즉, 한 번 더 LLM을 파인튜닝 해야 하고 그 비용은 어마무시할 것이다. (예시로 RepLLaMA - Fine-Tuning LLaMA for Multi-Stage Text Retrieval 참고)
이를 해결하기 위해 파인튜닝 없이도 LLM을 곧바로 임베딩 모델로 활용하는 시도들이 있었다. 그러면 디코더-only 모델인 LLM에서 어떻게 파인튜닝 없이 LLM을 임베딩 모델로 활용할까?
PromptEOL 방법론을 소개한다.
프롬프트를 사용해서 한 토큰에 최대한 문장의 정보를 압축하게 유도하는 방식인데, 다음과 같은 프롬프트를 넣어준다.
This sentence: [text] means in one word:
이렇게 긴 단락이나 문장을 하나의 단어로 요약하게 유도한다. 그러면 LLM이 생성하는 첫 번째 토큰의 마지막 layer hidden state를 곧 임베딩으로 활용하는 것이다. (혹은 마지막 layer의 모든 hidden state에 대한 mean pooling을 수행한다)
LLM의 마지막 layer의 output을 떠올려보자. LLM은 맨 마지막 레이어의 맨 마지막 hidden state 값을 다음 토큰 결정을 위한 확률 분포로 사용한다. hidden state는 그 앞 프롬프트의 토큰 개수만큼 더 있는 것을 기억하자.
그러면 왜 mean pooling을 수행하는 것 역시 하나의 방법인지 이해할 수 있다.
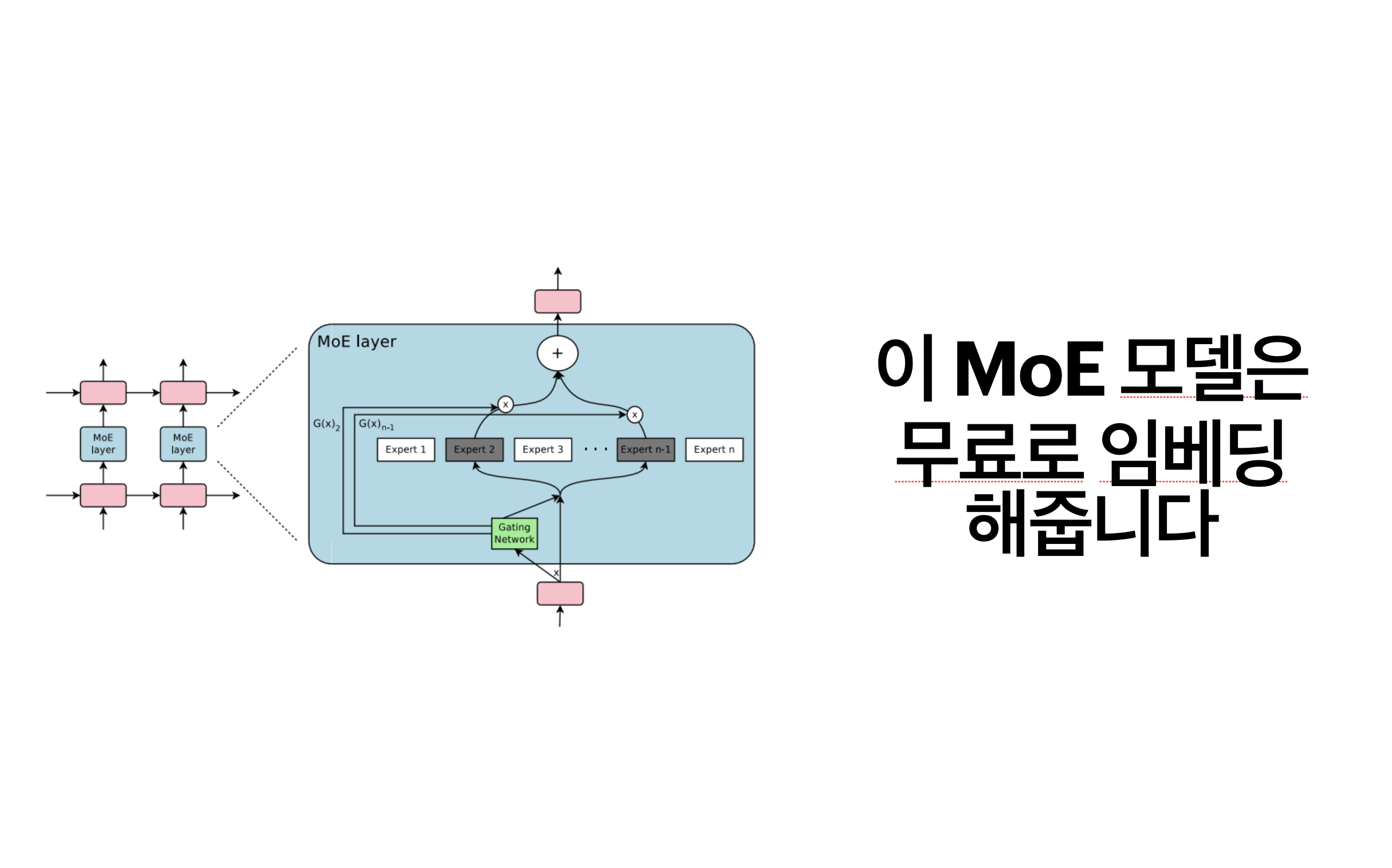
MoE LLM
Mixtral 모델을 기억하는가? 기억하지 못한다면 DeepSeek 모델은 모두 알고 있을 것이다. 이 두 모델의 공통점은 MoE를 사용한 것이다. 이 두 모델 뿐 아니라 MoE 모델의 구조를 채택하는 모델들은 매우 많아지고 있다.
MoE가 무엇인지는 인터넷 상에 자료가 너무나 많지만, 간단히 정리하면 LLM 내의 각 전문가들이 있고 MoE LLM 내부에서 주어진 프롬프트에 따라 가장 적합한 전문가들을 고른다. 전문가들은 어떤 특정 태스크에 적합한 네트워크가 레이어 별로 서로 분리가 되어 있다고 보면 된다.
(예를 들면 수학 전문가, 코딩 전문가, 물리 전문가와 같은 식으로...)
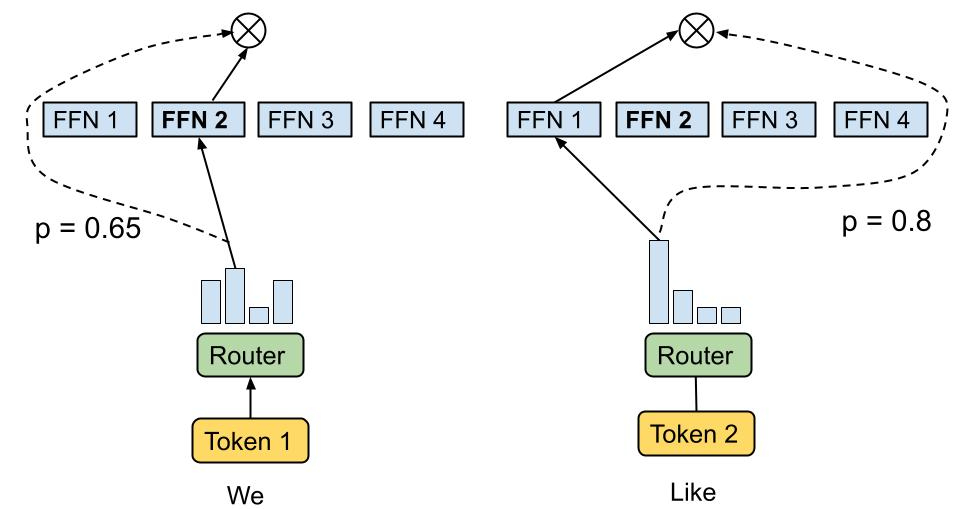
그러면 MoE LLM은 어떻게 적합한 전문가를 고를까? dynamic routing 매커니즘을 통하여 선정하게 되는데, 어떤 gating function을 지나면 주어진 input에 따라 각 전문가들을 사용할지 말지에 대한 확률 분포가 나오게 된다. 이것을 routing weights라고 한다.
MoEE (Mixture-of-Experts Embedding)
RW
먼저 위에서 말한 routing weights를 이용해 한 임베딩 벡터를 만들어보자.
한 레이어(
이제 모든 layer의 이러한 벡터를 다 모아서 첫 번째 부터 마지막까지 flatten해준다. 그러면 모든 레이어의 모든 expert 수 만큼의 차원을 가진 벡터가 완성된다. 이것이 바로 RW (routing weights) 임베딩이다.
수식으로 표현하면 다음과 같다.
RW와 Hidden State (이하 HS)와의 차이점 분석
논문에서는 기존에 많이 쓰던 HS와 MoE 모델에서 가져올 수 있는 RW와의 차이점을 분석해본다.
먼저 HS는 광범위하고, 문맥적인 정보가 많이 들어가는 한편 RW는 토큰 레벨의 아주 미세한 뉘앙스 적인 정보들에 집중한다.
이렇게 둘은 서로 상호보완적인 관계로도 볼 수 있고, 실제로도 다른 정보들을 포함하고 있는지를 조사해 보았다.

위 그림은 우리가 흔히 보던 word cloud인데, 어떤 식으로 만들었는지부터 설명해본다. 똑같은 문장들을 넣어서 각각 HS 임베딩과 RW 임베딩으로 바꾸었다. 그 후에 K-means를 적용하여 3개의 군집들로 나누었다. 이제 각 군집들에서 많이 언급되었던 단어들을 word cloud로 나타낸 것인데, 이 단어들이 각 군집을 대표하는 주제라고도 볼 수 있겠다.
사진에서 알 수 있듯이 각 군집들 간에 주제들이 HS와 RW가 많이 다른 모습을 볼 수 있다. 이는 각 임베딩 방법이 같은 문장들에서도 각기 다른 의미론적 부분을 catch해서 임베딩을 수행한다는 것을 의미한다.
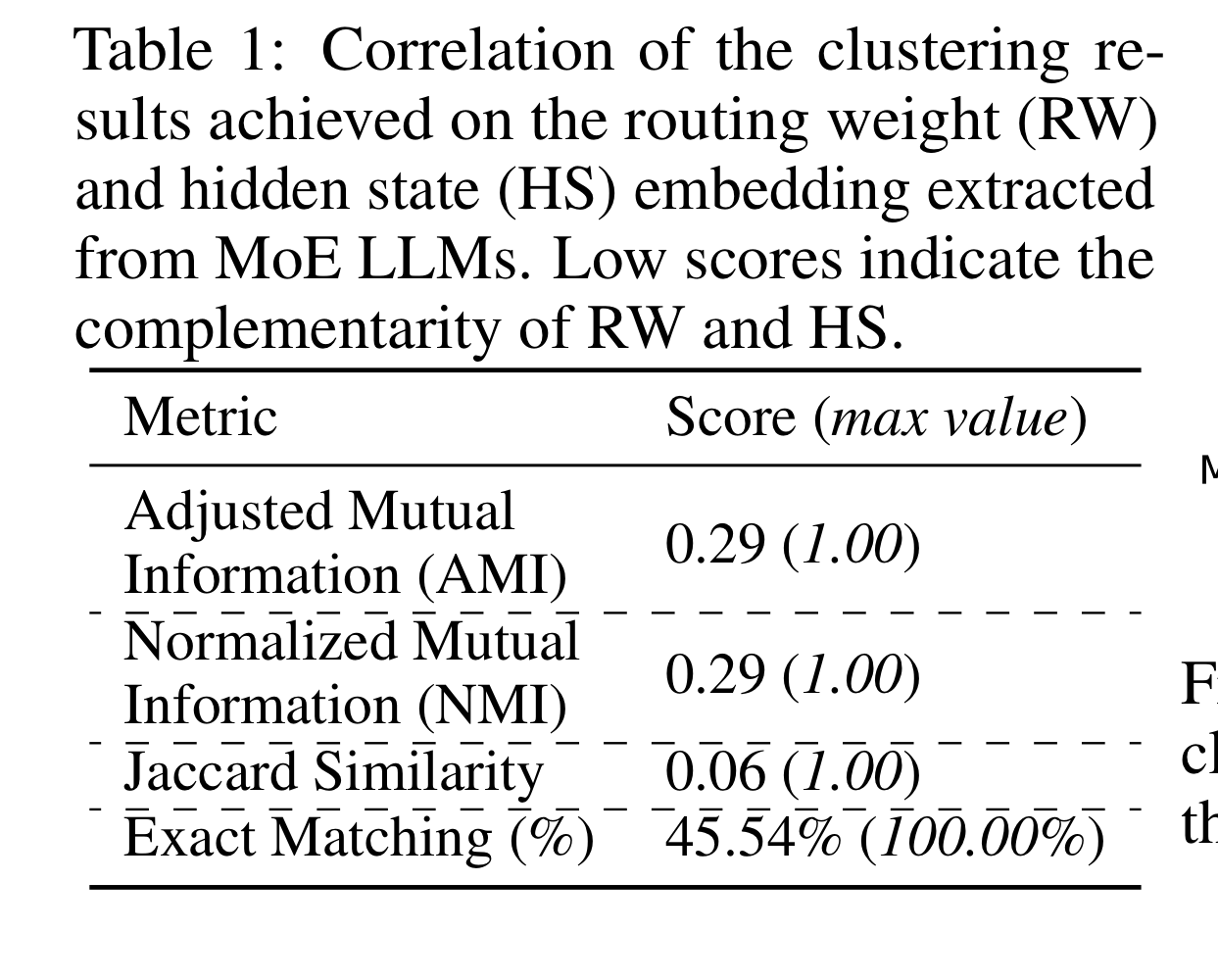
더불어 각 클러스터링 결과의 유사도를 비교했다. 만약 RW와 HS가 별반 다르지 않다면, 클러스터링 결과도 매우 비슷하게 나와서 유사도가 높게 나왔어야 할 것이다. 그러나, 표에서 볼 수 있는 것처럼 두 클러스터링 결과 사이에는 유사도가 높지 않았다.
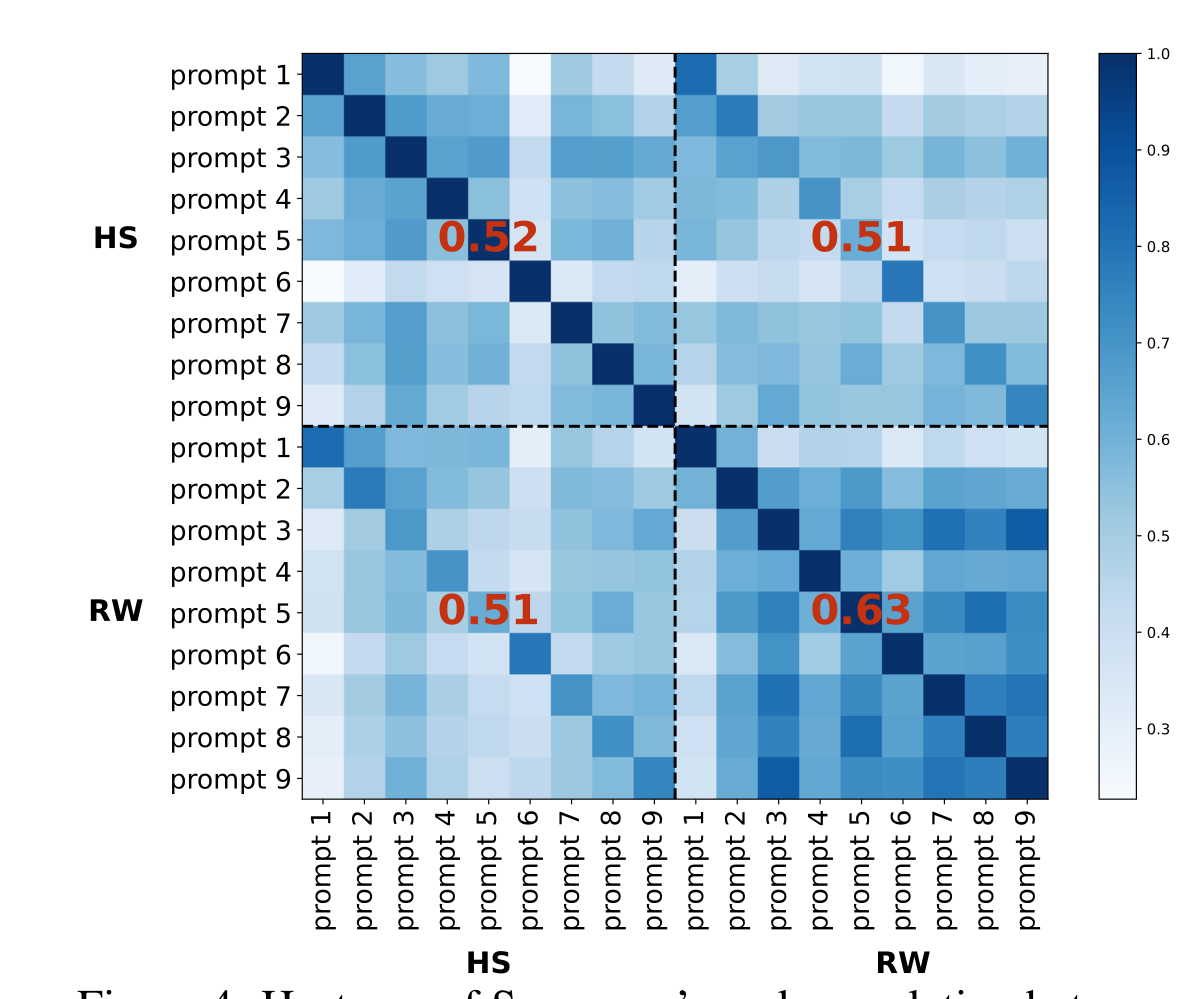
더군다나 이 그림을 보자. 한 문장의 임베딩을 생성하기 위해 9가지의 다른 프롬프트를 사용했고, HS와 RW 임베딩간의 correlation도 비교해 본 것이다.
오른쪽 위 혹은 왼쪽 아래에서 볼 수 있듯이 HS와 RW 임베딩 벡터 간의 차이는 9가지의 프롬프트 모두에서 평균 0.51 정도로 낮게 나타났다. 즉, 두 임베딩은 다른 측면들을 담고 있는 것이다!
추가적으로는, RW와 RW간의 임베딩은 0.63의 correlation이었지만, HS와 HS간의 correlation은 0.52였다. 즉, HS에 비해 RW가 프롬프트가 바뀌더라도 좀 더 일정한 (robust한) 임베딩 벡터 값을 보여준다는 것이다.
즉, HS와 RW는 서로 상호보완적이므로, 둘 다 쓸 수 있는 hybrid한 접근을 해보자
RW + HS => MoEE
그럼 어떻게 둘 다 쓸까? 두 가지 방법이 있다.
- MoEE (concat)
그냥 두 임베딩을 이어 붙히는 것이다. HS가이고 RW가 이라면 MoEE (concat)의 임베딩 벡터는 이 된다. - MoEE (sum)
HS 임베딩 벡터로 구한 cosine similarity()와 RW 임베딩 벡터로 구한 cosine similarity( )를 가중합해준다.
이렇게 MoE 모델에서 추가 파인튜닝 없이 임베딩 벡터를 구할 수 있었다! 그럼 성능은 어떠할까?
실험
MTEB에서 사용하는 6가지 태스크에 대해 성능을 테스트했다.
(분류, 클러스터링, pair classification, 리랭킹, Semantic Textual Similarity (STS, 유사도 점수 측정), 요약)
이 태스크들은 모두 임베딩 모델의 성능을 측정하는 것임을 기억하자.
다국어 데이터셋은 배제하고 영어 데이터셋으로만 성능을 측정했다고 한다.
또한 세가지 MoE 모델을 사용했다 (DeepSeekMoE-16B, Qwen1.5-MoE-A2.7B, OLMoE-1B-7B)
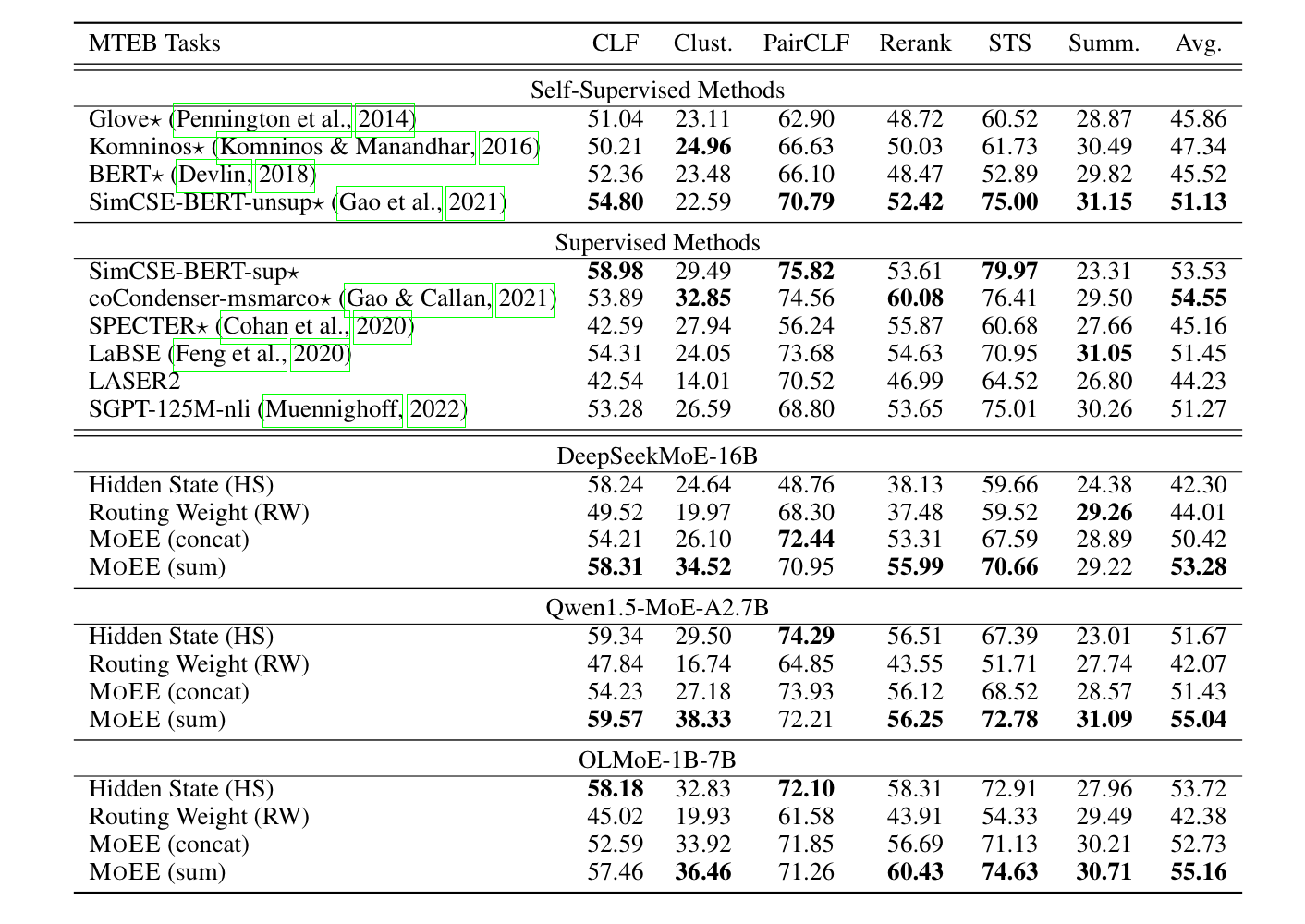
놀랍게도, 모든 태스크 평균 점수에 있어서 Qwen 및 OLMoE 모델의 점수가 가장 높았다. 각 태스크 별로 약간의 차이들은 있었지만, 전반적인 성능이 MoEE가 가장 좋았던 것이다.
여기서 주목할 점은 바로 위 벤치마크는 프롬프트를 사용한, 앞에서 소개한 PromptEOL 방식을 사용한 상태라는 것이다. 프롬프트를 사용하지 않고 사용한 경우에는 그 성능이 기존 베이스라인에 비해 떨어지는 모습을 보였다.
논문의 결과를 요약하면 MoEE를 사용한다면 PromptEOL 방식으로 프롬프트를 써주고, MoEE(sum) 방식을 사용하고 마지막 레이어의 마지막 토큰에 대한 HS를 사용하는 것이 좋은 성능으로 이어졌다고 한다.
결론
MoE 모델이 어떠한 전문가를 사용할까 고민하는 과정이 담긴 routing weights가 임베딩 벡터로서 활용이 되는 것이 놀랍다. 임베딩 모델도 결국에는 NLP 분야의 downstream task이고, 이 태스크의 성능을 높이기 위하여 LLM의 복잡하고 고도화된 언어 능력을 사용하는 것은 자연스럽다. 그런데 마지막 hidden state도 아니고 각 layer 별로 routing weights를 이용하는 것이 매우 재미있었다.
이런 식으로 LLM 내부의 여러 hidden state와 weight들이 다른 방식으로 의미 있게 활용이 될 수 있을 것이다.